
In this blog, we discuss various improvements that we have made to the proposed workflow first discussed in our previous blog post focused on edge processing of drone imagery for search-and-rescue. These improvements include the use of more capable hardware, improvements to the thermal and optical models, and the ability to geolocate detections in video to points on a map. This blog accompanies our talk at FOSS4G-NA on October 24, 2023.
To recap, as in the previous blog post, we are trying to answer the question:
How can we maximize search area and minimize viewing time?
That is, how can we replace the current practice of “hero” flying with something more systematic and automated. Pictorially: how can we go from flights that look like this:
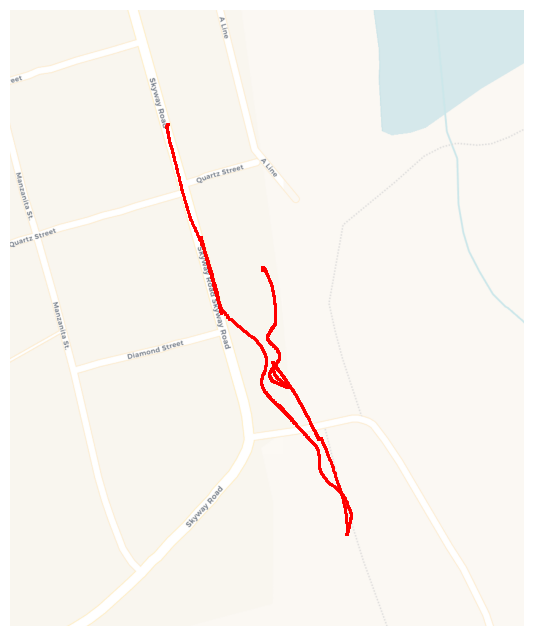
To flights that look more like this:
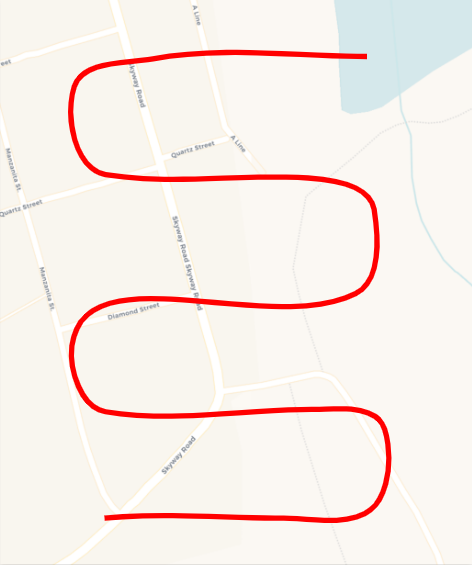
While delegating the task of detecting people to machine learning models.
More powerful hardware for faster detection
Instead of the AWS Snowcone, we chose to use a different edge device for this round of work, namely a Steam Deck. As a gaming console, the Steam Deck has the advantage of having a GPU, which is better suited for running our neural network-based detection models than the Snowcone’s CPU. In a recent companion blog, we go into more detail on how we deployed models on the Steam Deck using ROCm, ONNX, and PyTorch.
Optical model improvements
Previously, we had used an off-the-shelf pre-trained YOLOv7 [1] object detection model. While still good, this option was not very well-suited to overhead drone imagery since it had been trained on the COCO dataset [2] which primarily consists of natural images taken at the ground level.
To overcome this deficiency, we fine-tuned the COCO-pretrained weights on a combination of three other publicly available drone datasets: HERIDAL [3], NII-CU [4], and VisDrone [5], the first two of which are specifically designed for search-and-rescue scenarios.

This fine-tuning resulted in a noticeable improvement in detection performance as can be seen in the examples below.
Thermal model and thermal model improvements
Alongside the optical model, we integrated a thermal imagery-based classification model engineered for speed and efficiency. Our YOLOv7 object detection model is thorough but computationally intensive. Our thermal model is designed to quickly pre-assesses large volumes of video footage. It does that by partitioning each frame into sections and calculating the likelihood that a person is in a given area. Frames are assessed by the thermal model for maximum likelihood of a person being present anywhere within the frame. Areas of relatively high probability are reported to the optical model for further analysis.
We followed a multi-step process to develop this thermal model. Initially, we pretrained the model unsupervised on a large corpus of thermal videos to tailor it to the distinct features of thermal data. We then conducted additional pretraining on the HIT-UAV dataset [6], a good source of aerial thermal imagery.
To fine-tune the model for our specific needs, we used hand-collected samples from our target drone and thermal sensor. These samples included both positive and negative instances to train the model effectively.
In this phase of work, the quality of the thermal model has been improved, and the alignment of the thermal detection code with the target computer architecture has been improved.
Our dual-model architecture enables the thermal model to serve as a rapid triage mechanism. It scans incoming video, then flags sections likely to contain a person. Those sections then go through our more robust optical model for detailed object detection.

Geolocation
We explored the possibility of making the human review of captured videos and model detections more intuitive by transforming detections in video frames to points on a map. We did this by combining the drone’s flight metadata and its camera’s intrinsics and extrinsics with some trigonometry to get an approximate projection of pixel coordinates to ground coordinates.
This opens up the possibility of aggregating data from multiple different flights or different models onto the same map and the development of a GUI as we discuss below.
Future work
We finish off by highlighting some exciting future directions that might be worth pursuing as we continue to develop this work further. For more information you can learn about our Machine Learning capabilities on our website, and get in touch with our team to discuss how our expertise can be applied for your organization.
GUI
Having the ability to geolocate video frames and points within them enables us to build a GUI with an interactive map where the user might, for example, see at a glance what area has been covered by which flight, and even review subsets of the video by clicking a point on the map and having the part of the video that contains that point show up in the app. This is visualized in the mock-up below.
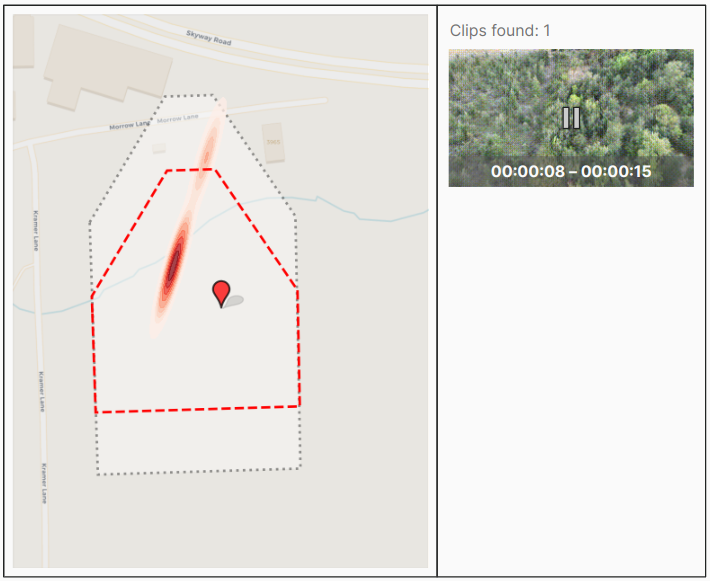
Tasking
Besides reviewing footage, a user might also be able to use the GUI to “task” future flights by, for example, drawing an AOI on the map. This ties into the Spatio-temporal Asset Tasking specification (STAT) which you can read more about here.
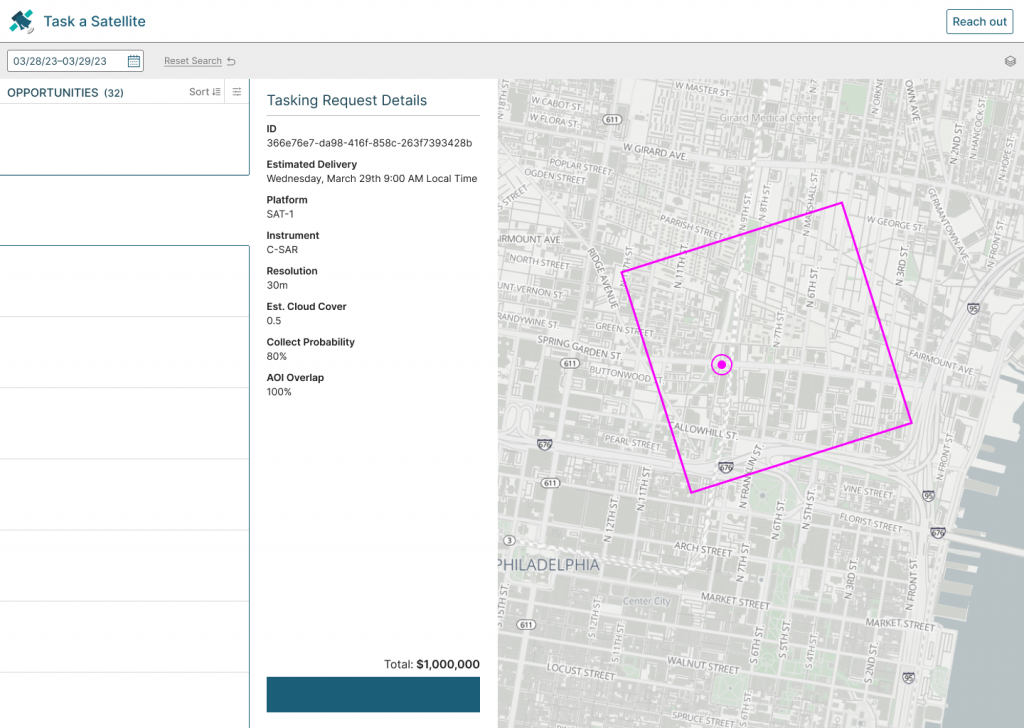
Contributors
This blog was authored by Adeel Hassan and James McClain.
References
[1] Wang, Chien-Yao, Alexey Bochkovskiy, and Hong-Yuan Mark Liao. “YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7464-7475. 2023.
[2] Lin, Tsung-Yi, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. “Microsoft coco: Common objects in context.” In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. 740-755. Springer International Publishing, 2014.
[3] Božić-Štulić, Dunja, Željko Marušić, and Sven Gotovac. “Deep learning approach in aerial imagery for supporting land search and rescue missions.” International Journal of Computer Vision 127, no. 9 (2019): 1256-1278.
[4] Speth, S., Gonçalves, A., Rigault, B., Suzuki, S., Bouazizi, M., Matsuo, Y. & Prendinger, H. (2022) Deep Learning with RGB and Thermal Images onboard a Drone for Monitoring Operations. Journal of Field Robotics, 1- 29. https://doi.org/10.1002/rob.22082
[5] Zhu, Pengfei, Longyin Wen, Dawei Du, Xiao Bian, Haibin Ling, Qinghua Hu, Qinqin Nie et al. “Visdrone-det2018: The vision meets drone object detection in image challenge results.” In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, pp. 0-0. 2018.
[6] Suo, J., Wang, T., Zhang, X. et al. HIT-UAV: A high-altitude infrared thermal dataset for Unmanned Aerial Vehicle-based object detection. Sci Data 10, 227 (2023). https://doi.org/10.1038/s41597-023-02066-6

