
“In Search and Rescue, we have to deal with the elements and rugged terrain, all while trying to find a missing person. We have to feel confident we haven’t missed something important.”
Lt. Trevor Skaggs
Butte County SAR, Training Officer
CALOES, Winter SAR Instructor
Element 84 has developed near real-time edge processing of drone and aerial imagery for human identification that leverages machine learning and AWS Snowcone edge capabilities during austere operations for search and rescue applications.
Edge Computing for Search and Rescue
When a person goes missing in rural Butte County California, Butte County Sheriff’s Search & Rescue (BCSAR) kicks off a Search and Rescue (SAR) mission. Volunteers for BCSAR report to the Search Base and begin a “hasty” search. During the “hasty” phase, SAR members search roadways, buildings, and any other high-probability places the missing person might be located. If the person is not found during the hasty search, the team plans/organizes and transitions to a systematic gridded search.
During the systematic search, ground searchers and drone operators will be given a geographic area to search with a higher level of confidence. Currently the flights are typically done “hero” style, where an operator actively flies the drone forward-facing so they can avoid obstacles while simultaneously viewing the footage and searching for signs of a person. The footage is also streamed/recorded and sent to the base camp for other SAR members to review. This means that 1) flights are not as efficient as they could be—some areas may be covered many times and others not at all—and 2) one minute of drone footage is reviewed in, at the very least, one minute of staff time. In practice, a single minute of footage could translate to several minutes of staff time for review. This inefficient system leads us to the question:
How can we maximize search area and minimize viewing time?
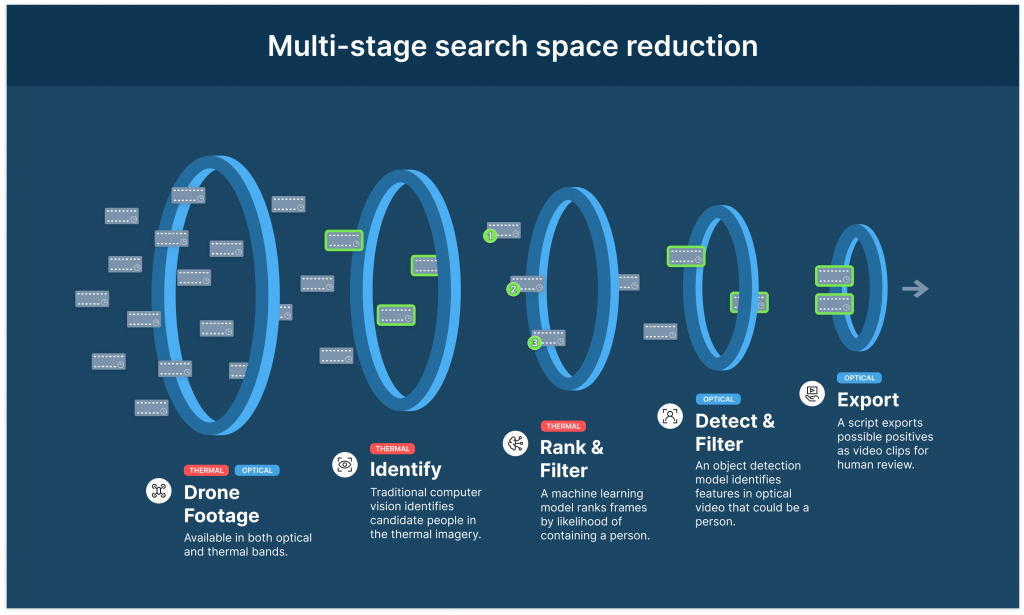
At Element 84, we have designed a workflow that the SAR team can operate in difficult environments to help them reduce the amount of time the team must spend reviewing footage. This workflow runs open source computer vision and machine learning techniques over drone footage loaded onto the rugged and portable AWS Snowcone. Several of the drones record video in both thermal and optical bands simultaneously. We use footage from both in our detection workflow, beginning with thermal.
Processing on the edge
Modern machine learning (ML) models need to be run on powerful hardware with GPUs or other accelerators. But, because the Snowcone is limited to 2 CPU cores with 4GB maximum memory, we must pare down our workflow as much as possible. To accomplish this, we take a multi-stage approach where we filter down the footage more with each step.
Given the hardware limitations of the Snowcone, running hours of drone footage through a machine learning model would be prohibitively time consuming. Instead, we adopt a two-stage approach where the video is first cut down (to the bits most likely to contain humans) by a light-weight model using thermal imagery and then further refined by a larger object detection model using optical imagery.
Additionally, we were able to squeeze some extra performance from our ML models by optimizing and quantizing our models using the open-source OpenVINO library. OpenVINO is a toolkit from Intel that allows users to optimize ML models from a number of popular libraries, including PyTorch, for x86 and Intel hardware (as well as some non-x86 and non-Intel hardware such as the Raspberry Pi).
Thermal Imagery
The thermal detection stage has two parts: a traditional computer vision-based algorithm and an ML model.
Computer Vision with OpenCV
The first step uses the ORB feature detection algorithm implementation in the OpenCV library to search for potentially interesting features in the thermal band. ORB, a nested acronym for Oriented FAST, Rotated BRIEF, detects features by determining whether something in an image stands out from the background. When run over optical imagery, it may be used to identify a corner or edge because of the sudden change in brightness, for example. In the thermal case however, the algorithm identifies areas that are suddenly either much warmer or colder than the background.
In the GIF below, we see a visual representation of the thermal imagery on the right, and the results of the computer vision algorithm and a lightweight thermal model (that will be discussed below) on the left. The neon green circles represent features identified by the ORB algorithm and the intensity of red is correlated with the inferred probability of there being a person in that part of the image (the probability-inference method is discussed more below).

Machine Learning with PyTorch
After identifying features in the thermal band, we use a lightweight machine learning model to find frames in the video that are most likely to contain humans. As we can see in the gif, the traditional computer vision algorithm identifies humans (the small dots that often move around) as features, but it also identifies vehicles (the larger rectangular objects), and even a roadway as features. We needed a way to discriminate between features centered on people and features not centered on people.
We dealt with that by using PyTorch to train a lightweight machine learning model on which areas of a given frame, represented by 112 by 112 pixel squares centered on the ORB-generated features, are assessed for their probability of containing humans. The model produces a number between 0 and 1 that is correlated with the probability of there being a person in the given square. The model output is represented by purple squares in the left side of the gif above, with more intense purple correlated with greater probability of the square containing a person.
The inferred probabilities are used to suggest times in the video when people are likely to be on-screen. Those suggestions are encoded in JSON files which are then passed to the next stage of analysis.
Despite the fact that this ML model was designed to be relatively lightweight, we found that there was room for further optimization. Using OpenVINO, we were able to reduce the memory footprint by a double-digit percentage and increase the speed of the model on the Snowcone’s CPU by a triple-digit percentage.
Optical Imagery
Object detection with YOLO v7
In the optical detection stage, we run an object detection model on the segments of video identified by the thermal detection stage as likely to contain people. For this application, we used the YOLO v7 architecture, one of the newer entries in the YOLO (You Only Look Once) family of real-time object detection models. For now, we are using off-the-shelf pre-trained weights that are not specifically optimized for overhead drone imagery, but in the future, it is likely that we can get a major boost in detection quality by training on a dataset more specialized to the SAR task.
The GIF below shows the “person” class in the results, along with a confidence level, represented as a decimal between 0 and 1. Critically, towards the end of the gif loop, there is a person in the shade of a tree that the model correctly flags. The drone operator who conducted this flight reports that he was not able to discern that person while actually flying the drone.
OpenVINO was again critical in optimizing the model’s runtime performance on the snowcone, providing about a 4x speedup.
Timestamps of frames identified by the YOLO model as likely to contain a human were again exported as a JSON file that is then fed into the video clipping script to create video clips for human review.
Model Performance
So far, our results indicate that this direction for developing edge computing workflows is likely to be fruitful. To date, we have tested the entire multi-phase filtering workflow on relatively short test videos that contain lots of people. For these types of artificial footage, the model can filter the footage to the frames that need human review at a speed of about 3 minutes for 1 minute of footage. The model runs slowly on highly populated videos because few frames can be immediately discarded. In test videos more faithful to real life search conditions, most of the video will be unpopulated wilderness, where most of the footage will likely be discarded after the thermal stage. We are confident that speeds will increase when the model is applied to more realistic footage.
Training the machine learning components of the workflow on additional training data will likely also improve model performance. For this demonstration, we used a model for the object detection phase that was trained on images of people taken from the side rather than top-down. Creating labels for people in those more realistic training videos described above will also allow us to improve the efficacy of the model when applied to drone footage rather than terrestrial videos.
Open source resources
Other resources
- White paper — Disaster Response: User needs review and project considerations for improving disaster response data pipelines
- AWS Snowcone announcement press release
Contributors
Derek Dohler, Adeel Hassan, James McClain, Trevor Skaggs, and Eliza Wallace
