Just to be upfront and get it out there: no. Despite what you may have heard, Zarr is not (yet) a replacement for the Cloud-Optimized GeoTIFF (COG) format. Zarr is great for Level 3 and Level 4 n-dimensional data cubes. COG is great for Level 1, Level 2, and other non-data-cube rasters.
Enthusiastic Zarr users have found a hammer they really like–for understandable reasons–and are now looking for more nails to use it on. But everything might not be a nail, and Zarr might not be the right hammer for everyone.
Even so, it turns out Zarr and COG are not that different, not really. We think the community is approaching this inflection point the wrong way, and that we should be doing more to find common ground and common solutions. Instead of pitting these formats against each other we should make them work together.
Throughout this post we’ll be referencing a Juypter Notebook we put together to support our arguments. Those curious about the deeper technical side can look at that notebook to see how we went about proving our ideas.
Why are we talking about this now?
At the Cloud Native Geospatial conference earlier this month we were struck by the amount of hype around the Zarr data format. And we get it! Zarr is awesome! It’s flexible and n-dimensional, making it a great format for data cubes.
But we heard many contentious opinions regarding Zarr and its relation to the entrenched COG format for storing non-ARD raster data. Also, the stakes are about as big as they can get given recent news:
- ESA has announced the Earth Observation Processing Framework (EOPF) data format leveraging Zarr as the new format for Sentinel 1, 2 and 3, despite concern and pushback from some in the community.
- Zachariah Dicus from USGS EROS presented on work benchmarking Zarr as a data format for Landsat’s archive, indicating Zarr is being considered as a replacement for the current COG format.
What makes COG and Zarr seem different?
It can be genuinely hard to tell what the differences are between these two data formats because the common defaults are different. You might have larger chunks in a Zarr store than the analogous tiles in a COG. Compression algorithms are likely to be different (the default for zarr-python is zstd, whereas COGs often use deflate for backwards compatibility).
In Python, even accessing data is significantly different between COG and Zarr: using xarray to access data in an object store leverages the zarr-python library to read Zarr stores, and the rasterio library for COGs. Each of these libraries uses different dependencies to make requests and decode data. Knowing what is actually going on behind the scenes can be really hard: benchmarking the exact same data stored in a Zarr and a COG might just be measuring the differences between these client libraries.
It’s important to keep in mind that these are not real differences in the formats themselves – just different choices for defaults and implementations. In the rest of this post we will lay out some of the actual differences between these formats. If we dig deeper into both, if we understand how each stores the data contained within its files, we may start to understand what we have here is not necessarily a discrete choice. Zarr and COG might not even be in opposition. We might even begin to see them as complimentary to each other.
How are COG and Zarr the same?
COG and Zarr both store metadata for the whole array, store array data as (optionally compressed) binary values, and allow partial reads – they are, in fact, similar in many ways. The metadata fields are generally the same. Assuming the same compression, filters, and tiling schemes are used to encode an array into both formats, COG and Zarr use the exact same byte representation of the array data on disk (and over the network).
We prove this in our notebook. We take a COG and read the compressed byte of a tile out of it, then we convert the COG to Zarr using the same compression, filters, and tiling scheme. Reading the same compressed chunk of the Zarr and comparing it to our COG tile shows the bytes to be identical!
# we read the bytes for tile (0,0)
with (COG_FILE).open('rb') as tif:
tif.seek(cog_tags['TileOffsets'][0])
cog_tile_bytes = tif.read(cog_tags['TileByteCounts'][0])
# we read the zarr chunk file for (0,0)
zarr_deflate_tile_bytes = (ZARR_DEFLATE / 'red' / 'c' / '0' / '0').read_bytes()
# we print out the size and sha256sum of each byte string
describe_bytes(cog_tile_bytes)
describe_bytes(zarr_deflate_tile_bytes)
# outputs:
# size: 1.381 MiB | shasum: 2c02e7e60074d6767ccb4c44de2da249d331fd82e107431e41cfe4069bae0d62
# size: 1.381 MiB | shasum: 2c02e7e60074d6767ccb4c44de2da249d331fd82e107431e41cfe4069bae0d62
Are there actual differences between COG and Zarr?
So if the data bytes are the same, are there differences? Yes! The first real difference is flexibility. Zarr is able to support large scale n-dimensional arrays, and a single Zarr store can have multiple groups of arrays with unrelated dimensions. Zarr also allows for each array to have a different data type.
COG, at least in common usage, is more frequently associated with 2D data, which is perhaps unsurprising given that COGs are TIFF files and images are relatively 2D. COG does support multiple dimensions within an array as long as all have the same size and data type, and it can support multiple unrelated arrays. Even so, such usage is uncommon and less usable than Zarr where label support makes larger datasets much more manageable and understandable (though this limitation is mostly due to a lack of tooling to make using such COGs manageable–it’s not really a limitation of the format itself).
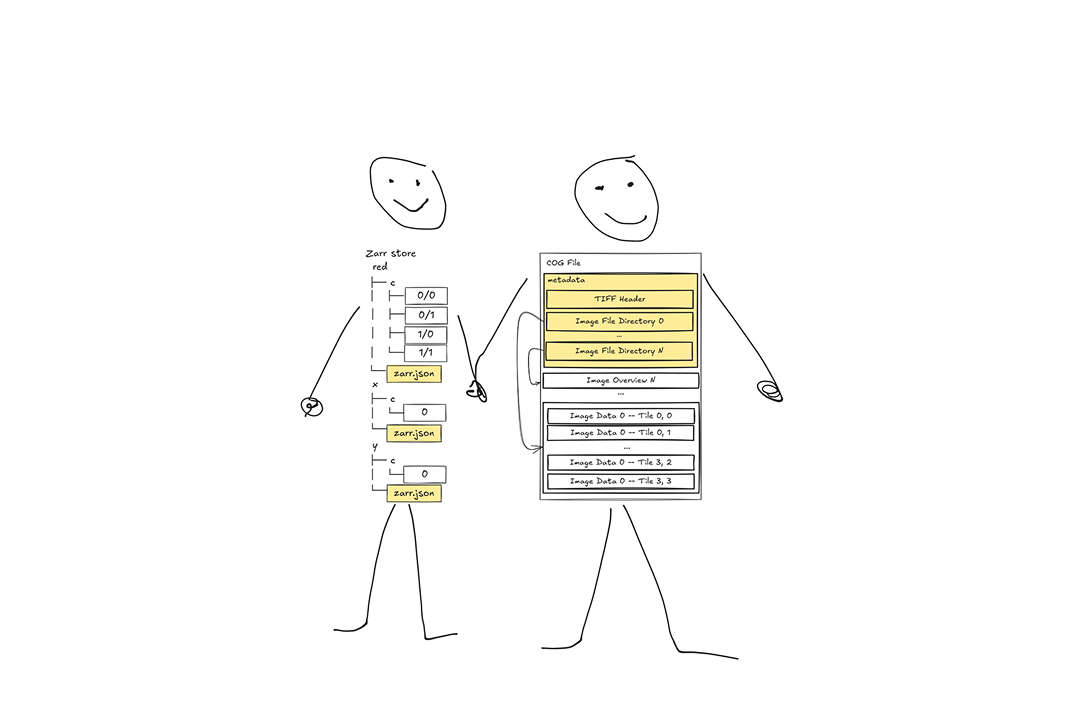
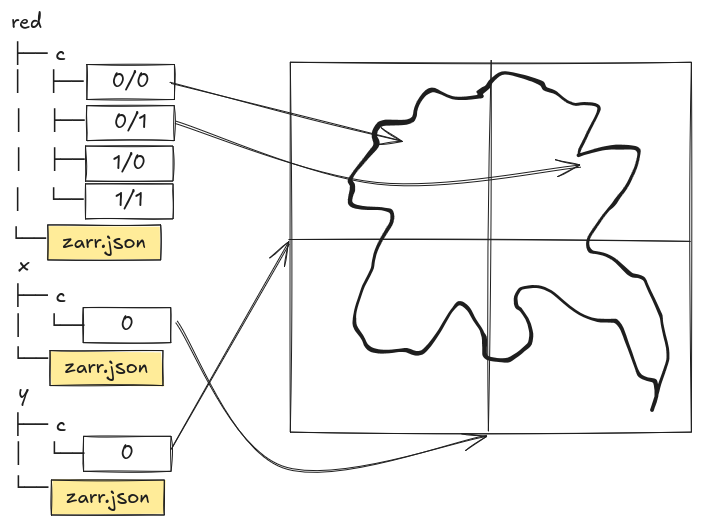
Another key difference is file structure. A COG is a file, whereas Zarr typically consists of a directory of files containing metadata files (json) and data files (binary) arranged in a hierarchy that allows you to access a particular chunk of data according to its filepath. This difference in structure is actually reflected in one of the only metadata content differences: the metadata in a COG is often dominated by the tile index information that stores the byte offsets and lengths of the array tiles, where Zarr offloads this index to the filesystem, relying on filesystem lookups to find the location and length of the bytes on disk containing a given chunk of data.
{
"ImageWidth": 10980,
"ImageLength": 10980,
"BitsPerSample": 16,
"Compression": 8,
"PhotometricInterpretation": 1,
"SamplesPerPixel": 1,
"PlanarConfiguration": 1,
"Predictor": 2,
"TileWidth": 1024,
"TileLength": 1024,
"TileOffsets": [55962680, 57411167, 58810332, 60222446, 61651003, ...],
"TileByteCounts": [1448479, 1399157, 1412106, 1428549, 1403985, ...],
"SampleFormat": 1,
"ModelPixelScaleTag": [10.0, 10.0, 0.0],
"ModelTiepointTag": [0.0, 0.0, 0.0, 600000.0, 5100000.0, 0.0],
"GeoKeyDirectoryTag": [1, 1, 0, 7, 1024, 0, 1, 1, 1025, 0, 1, 1, 1026, ...],
"GeoAsciiParamsTag": "WGS 84 / UTM zone 10N|WGS 84|",
"GDAL_METADATA": "<GDALMetadata>\n <Item name=\"OVR_RESAMPLING_ALG\">AVERAGE</Item>\n <Item name=\"STATISTICS_MAXIMUM\" sample=\"0\">17408</Item>\n <Item name=\"STATISTICS_MEAN\" sample=\"0\">1505.1947339533</Item>\n <Item name=\"STATISTICS_MINIMUM\" sample=\"0\">294</Item>\n <Item name=\"STATISTICS_STDDEV\" sample=\"0\">659.24503616433</Item>\n <Item name=\"STATISTICS_VALID_PERCENT\" sample=\"0\">99.999</Item>\n <Item name=\"OFFSET\" sample=\"0\" role=\"offset\">-0.100000000000000006</Item>\n <Item name=\"SCALE\" sample=\"0\" role=\"scale\">0.000100000000000000005</Item>\n</GDALMetadata>",
"GDAL_NODATA": "0"
}
Example GeoTIFF image metadata, decoded from binary tags
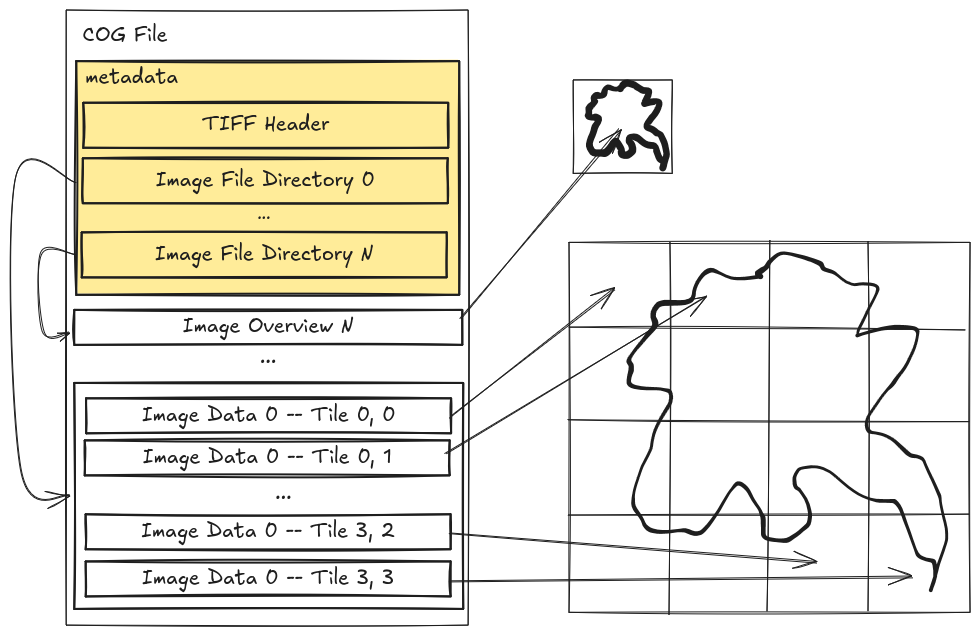
Metadata storage and access also differs between the two formats. COG encodes the metadata using TIFF tags, which are essentially a binary key/value store. As the metadata in a COG is part of the same file as the data, reading the metadata is potentially a bit of a guessing game. COG enforces that all metadata be located at the beginning of the file so clients can read the first n-bytes of the file with the hope that they get all the metadata in a single read. As TIFF metadata is stored quite efficiently in binary format, clients should be able to get it all by reading the first 32KB of a COG, except in the case of extremely large files.
{
"shape": [10980, 10980],
"data_type": "uint16",
"chunk_grid": {
"name": "regular",
"configuration": {
"chunk_shape": [1024, 1024]
}
},
"chunk_key_encoding": {
"name": "default",
"configuration": {
"separator": "/"
}
},
"fill_value": 0,
"codecs": [
{"name": "bytes", "configuration": {"endian": "little"}},
{"name": "zstd", "configuration": {"level": 0, "checksum": false}}
],
"attributes": {
"STATISTICS_MAXIMUM": 17408,
"STATISTICS_MEAN": 1505.1947339533,
"STATISTICS_MINIMUM": 294,
"STATISTICS_STDDEV": 659.24503616433,
"STATISTICS_VALID_PERCENT": 99.999,
"scale_factor": 0.0001,
"add_offset": -0.1,
"_FillValue": 0
},
"dimension_names": ["y", "x"],
"zarr_format": 3,
"node_type": "array",
"storage_transformers": []
}
Example zarr.json file contents of Zarr array JSON metadata
Zarr, on the other hand, uses text in JSON format stored in its own file per array, which allows reading the complete metadata without any guessing at length. Zarr also supports a concept called “consolidated metadata”: Zarr groups can put the metadata of all their enclosed arrays together into a single file at the root of the group, allowing clients to fetch all the metadata for the entire group in a single read. While the JSON metadata format is not as efficient for storage and transfer (and likely parsing) as TIFFs binary format, JSON is human-readable and writable and allows for easier inspection and extensibility.
The last big difference is how coordinate data is stored. COG supports multiple metadata-based mechanisms for storing georeferencing information. Most commonly this is via an affine transform, which can be used to convert coordinates between image space and model space, allowing the data to be georeferenced per pixel. Zarr, on the other hand, stores the fully realized coordinate values of every cell in their own arrays. (It is worth noting that GeoTIFF has been an accepted specification for storing geospatial data in TIFFs since 1994, while the GeoZarr spec currently appears to be a long way from achieving any sort of consensus as to how to store this equivalent information).
Instead of COG vs Zarr, is it COG and Zarr?
Certainly Zarr has advantages for n-dimensional data on a common grid. COG obviously has advantages for 2D data as an entrenched standard with wide compatibility. Each format has strengths and weaknesses that allow for both to coexist within their niches.
It could be easy to end here and say kumbaya, we should just let people use both of these formats if they want and not worry about fighting. Except that would be boring.
Remember how any data that can be stored as a COG can also be stored in a Zarr store?
As previously mentioned, Zarr normally uses the file system as an implicit index of its contents. But with Zarr 3 came a new Sharding Codec that allows storing multiple chunks within a single file. Zarr needs sharding because:
- It becomes difficult to manage all the files in a store when every chunk is a separate file
- We can reduce the number of GET requests required to read a set of chunks by grouping requests to read multiple contiguous (on disk) chunks into single GET requests, increasing the efficiency of reads
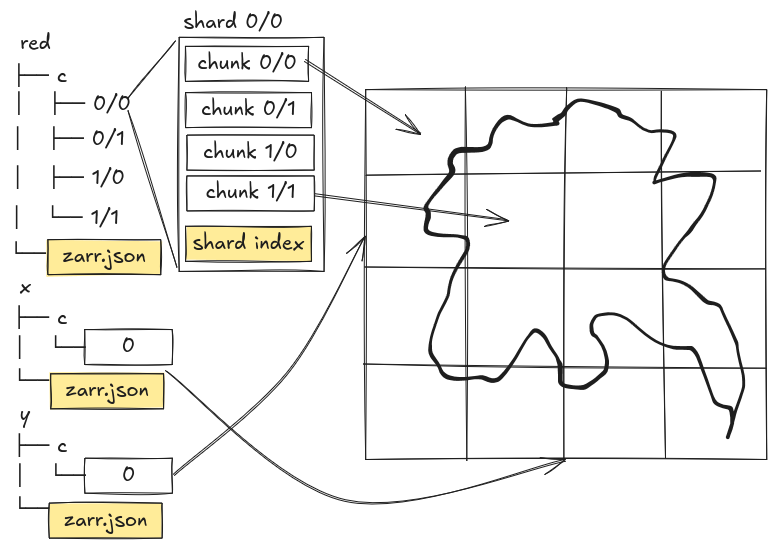
But doesn’t a shard–a file containing multiple chunks–sound familiar? Like maybe, could we use…
…could we use a COG as a shard?!?
It turns out…we can!
Check out the linked notebook, where we show exactly this. To make this work, we do have to modify our COG by writing the Zarr shard index to the end of it. But it is still a valid TIFF and valid COG, even if it is subtly modified. In doing so we can now choose how we want to work with the data: do we want to access it as a Zarr using xarray and other common Zarr tooling? Or do we want to use the shard directly as a COG and work with it using any number of compatible tools and applications? We can choose!
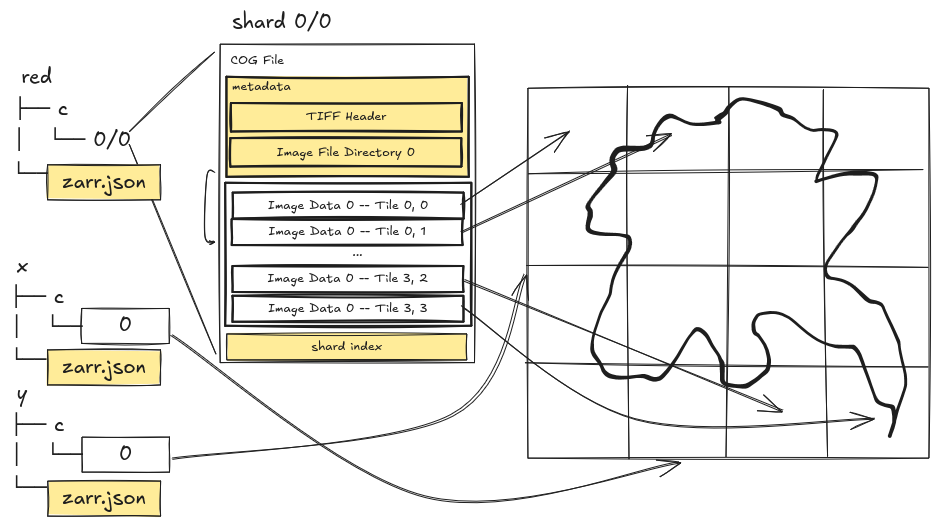
Interestingly, the way Zarr implements sharding actually appears to offer an opportunity to create a custom storage codec that can read COGs natively–meaning no need to write the shard metadata to the end of the file, the regular COG metadata could be used just as easily to index the tiles as Zarr chunks. We are even hoping to put together a proof of concept implementation of this idea as part of future work.
Um…what about Virtualizarr?
We’d be remiss not to mention that VirtualiZarr is a compelling effort to do exactly what we are proposing here, to get Zarr to play well with an existing data format. But VirtualiZarr aims to make non-cloud-optimized formats usable in a cloud-optimized way–which isn’t necessary for COG, as it is already cloud-optimized. VirtualiZarr also requires duplicating the largest piece of metadata, the tile/chunk index, from the COG to the VirtualiZarr metadata.
We want to take this effort a step further, because we see no reason COG and Zarr cannot be more tightly integrated. We also see potential benefits of doing so, such as allowing Zarr access via large virtual chunks via the concept of “metatiles”, while retaining smaller tiles internally within the COG, allowing two different access patterns to better align with different use-case.
What should we actually be thinking about?
So if this isn’t a matter of COG or Zarr, then what is it?
The disagreement here is a real symptom of a real problem. To us, that problem is multifaceted, but ultimately one of uncertainty around how to optimally store array data to meet modern user expectations while also minimizing storage and processing costs in the face of ever-growing data archive sizes. We believe these concerns are actually less about data formats, COG or Zarr, and more about how the data is stored within a COG file or Zarr store. Some questions we should be asking include:
- What compression/filters should you use for your data?
- What should the tile/chunk size and metatiles/shard organization be within the file (z-order?)?
- What metadata should you store per-array? What about aggregated array statistics?
- Should you store overviews that allow easy access to the data at different resolutions?
The answers to these questions are not one-size-fits all, often depending greatly on how you expect people to use the data. For instance, if you anticipate that the data will be used primarily for visualization, you likely want to use smaller chunks that can load quickly. Whereas if you expect the data to be used as part of large-scale analyses, you probably need a bigger chunk size to optimize chunk access patterns and to get better compression ratios. But talking about chunk sizes or compression algorithms is generally a good way to get peoples’ eyes to glaze over. And when the answer is “it depends,” people start looking around for another, easier answer. Like maybe it would just be better to switch to a “different format.”
Ultimately, the community needs to provide sufficient guidance to data producers to empower them to make choices about how to best store their data depending on their anticipated access patterns. We need to do more research to understand how different choices affect storage and access efficiency under different usage scenarios. We need to dig into library and application compatibility and present those findings to producers.
We also need to work more on our tooling, both to help produce better data, and to consume data more efficiently. Tooling can be used to great effect to enforce best practices and to write data in more efficient ways (for example, by enabling more advanced tile organization patterns within a file/shard). We also see differences in performance in client libraries when reading the same bytes, depending on format. Such findings are likely indicative of advances in programming practices and optimizations that have not made it into older, more mature software libraries (such as libtiff). By investing in modernizing existing libraries, and building better shared layers we can leverage across our geospatial ecosystem regardless of data format, we can ensure all users benefit from our work.
Utopian Vision #1: Everyone just does Zarr
One version of utopia could be “what if there were just one canonical data format for all array data.” Then everyone could use the same tooling, and specs like icechunk could come along and improve things for everyone all at once.
Why is this not a compelling vision?
Because COGs already exist, and it turns out they work really well for a lot of applications. They are well-understood and supported by a robust array of tools in a variety of languages. COG is the canonical distribution format for Landsat and other satellite missions. Even if somehow it made sense to stop writing all COGs today, we would still need to be able to read those COGs that already exist, necessitating us to maintain the existing tooling.
Utopian Vision #2: We all work together
Let’s take a look at what we are using client-side. How can we take the modernization that has happened in Zarr and apply those ideas to COG readers?
To what extent can we build off a common foundation of some key core libraries? Examples of this include the rust object_store crate, the async-tiff project (which is using object_store), and the new python bindings exposed by the python obstore library. Can we build a shared layer for all common codecs, to be able to use the same codecs across each format? The data formats are so similar–reading the data should be exactly the same with access merely controlled by different high-level interfaces layered on top.
Conclusion
We think the vision of working together is much more interesting and attractive than the alternative. Zarr is obviously a good idea–it has a ton of momentum behind it for a reason. But COG has proven itself to be an excellent format. We should work to leverage the strengths of both formats, and learn from each.
No matter what course we choose, we have a lot of work to do. So let’s work together, not work to divide ourselves.
Relevant talks from the CNG Conference
CNG was a great conference, especially for us data format nerds who love discussing these byte-level details. Here are some of the talks we went to that we think were particularly relevant to this topic:
- Zarr for Cloud-native Geospatial. When and Why? (Lindsey Nield & Deepak Cherian)
- Cloud Native Geospatial in Earth Engine: COGs and Beyond (Sai Cheemalapati)
- Zarr: Landsat Trade Study at Scale (Zachariah Dicus)
- Are COGs Actually Scaleable? (Jeffrey Albrecht)
- Zarr, Icechunk, & Xarray for Cloud-native Geospatial Data-cube Analysis (Deepak Cherian, Joe Hamman, Emma Marshall, Tom Nicholas, Lindsey Nield)
- Helping Restore Nature with Cloud-Native Geospatial (lightning talk; Martha Morrissey)

