In this post, I’ll outline the process we used to convert geodatabase files with vector data and related tabular data to vector tiles for use in a web application.
We’ll walk through the data processing pipeline in the context of the NJ Wildlife Habitat Finder, a tool that generates a list of protected species habitat within the user-selected Area of Interest. Read the project intro blog post to learn about why we chose to work with this statewide wildlife habitat dataset of almost 1 million polygons.
Follow along with the steps to learn how to use multiple open source libraries and tools including GDAL ogr2ogr, Mapbox Tippecanoe, Turf.js, and Mapbox GL JS to process a geodatabase into vector tiles and create an interface that enables custom queries.
Data processing
Downloading data
Landscape Project wildlife habitat data is available as open data. The State of New Jersey is divided into 6 regions and a separate geodatabase is provided for each region.
Since the files shared a common source URL, we were able to write a script to programmatically download the data.
First, we created a CSV of landscape region names. We wrote a loop that downloaded the data with Wget, unzipped the download, and restructured the directory to move the geodatabase outside the downloaded folder for each line in the CSV.
# download Landscape Project Version 3.3 File Geodatabases from http://www.nj.gov/dep/gis/landscape.html
for region in $(cat /usr/src/nj-habitat-regions.txt)
do
wget -P /usr/src/gen/downloads http://www.state.nj.us/dep/gis/digidownload/zips/landscape/${region}_v3_3gdb.zip
unzip -d /usr/src/gen/downloads/${region} /usr/src/gen/downloads/${region}_v3_3gdb.zip
mv /usr/src/gen/downloads/${region}/${region}_v3_3.gdb /usr/src/gen/landscape-project-3-3/${region}.gdb
done
Converting data to open formats
While it’s possible to use geodatabase files in desktop GIS software, open formats are required for the creation of vector tiles.
We used ogr2ogr to convert the components of the geodatabase to open data formats. We converted the vector data files within the FileGDB to GPKG files. Then, we converted the associated tabular data to CSV files.
We provided the function below with the landscape region ({1}), vector data ({2}), related table ({3}) to convert files for each landscape region:
function convert_data() {
echo "PROCESSING ${1} : GPKG"
ogr2ogr -skipfailure -overwrite -t_srs 'EPSG:4326' -f 'GPKG' /usr/src/gen/${1}_habitat.gpkg /usr/src/gen/landscape-project-3-3/${1}.gdb ${2}
echo "PROCESSING ${1} : CSV"
mkdir -p /usr/src/gen/tmp
rm -r /usr/src/gen/tmp
ogr2ogr -skipfailure -overwrite -f 'CSV' /usr/src/gen/${1}_species.csv /usr/src/gen/landscape-project-3-3/${1}.gdb ${3}
mv /usr/src/gen/tmp/${3}.csv /usr/src/gen/${1}_species.csv
}
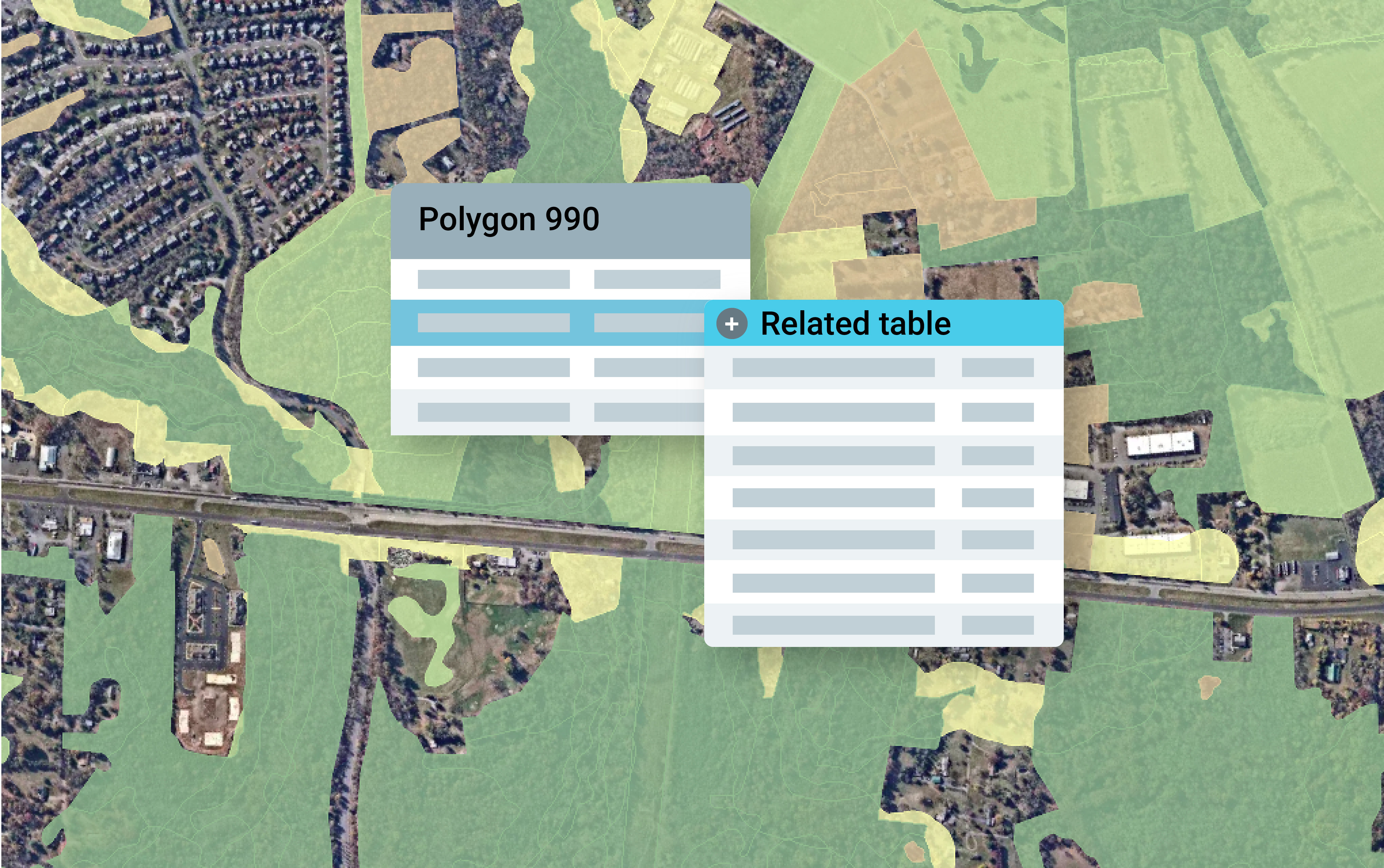
Relating tabular data to vector data
You’ll need to identify the relationship between the vector data and related tabular data. You’ll also need a common ID field in both files to accurately relate the data.
In this example, there is a many-to-one relationship between the species information tables and the vector data. For example, one polygon could be valued as habitat for multiple species. There could also be numerous sightings of the same species associated with the polygon.
Landscape Project habitat polygons each have a unique ID value. The related table information has matching ID values, which makes associating the data set straight-forward.
To prepare the data for client-side requests, we needed to append the species sighting data to the vector data.
Appending related table data to vector data property
Next, add the tabular data to the vector data. If you’re working with data that has a one-to-one relationship, you can append the related table information as a property in the vector data set. If the data has a many-to-one relationship, one method for associating the data is to append the data as a list of JSON objects within a vector data set property. To use this method, follow the steps below.
To record all species information for each polygon, we created an empty list for property species in the vector data file.
# Collection of habitat features with species sightings, organized by LINKID
habitats = {}
# Register format drivers with a context manager
with fiona.drivers():
print("Processing {}".format(habitat_path))
# Open the habitat geopackage data
with fiona.open(path=habitat_path) as habitat_data:
# For each polygon feature in the habitat dataset...
for feature in habitat_data:
# def process_feature(feature):
# The unique LINKID for the feature
link = str(feature['properties']['LINKID'])
# If this is a new feature...
if link not in habitats:
# Clean feature data
del feature['id']
if 'VERSION' in feature['properties']:
del feature['properties']['VERSION']
if 'HECTARES' in feature['properties']:
del feature['properties']['HECTARES']
if 'SHAPE_Length' in feature['properties']:
del feature['properties']['SHAPE_Length']
if 'SHAPE_Area' in feature['properties']:
del feature['properties']['SHAPE_Area']
if 'SHAPE_Length' in feature['properties']:
del feature['properties']['SHAPE_Length']
# Add empty list for collecting sightings
feature['properties']['species'] = []
# Add this feature to the habitats collection under its LINKID
habitats[link] = feature
Then, we processed each line of the related table CSV files into a JSON format and populated a features.txt file, where each line was a separate wildlife habitat record JSON object.
Next, we referenced the features.txt file and pulled any line with a matching ID into the associated species property list. Each JSON object in the list represented data for one line in features.txt.
# Open the species csv data
with open(file=species_path) as species_data:
species = csv.reader(species_data)
headers = next(species, None)
# Find the indexes of the columns we'll use
link_index = headers.index('LINKID')
class_index = headers.index('CLASS')
comname_index = headers.index('COMNAME')
sciname_index = headers.index('SCINAME')
fed_status_index = headers.index('FED_STATUS')
nj_status_index = headers.index('NJ_STATUS')
feat_label_index = headers.index('FEAT_LABEL')
max_year_index = headers.index('MAX_YEAR')
cnt_soa_index = headers.index('CNT_SOA')
fha_scdw_index = headers.index('FHA_SCDW')
fha_tsc_index = headers.index('FHA_TSC')
# For each row in the species csv data...
for row in species:
# Get the LINKID
link = str(row[link_index])
# Create a data object for this row
data = {}
# Record the important fields
data['CLASS'] = row[class_index]
data['SCINAME'] = row[sciname_index]
data['COMNAME'] = row[comname_index]
data['FED_STATUS'] = row[fed_status_index]
data['NJ_STATUS'] = row[nj_status_index]
data['FEAT_LABEL'] = row[feat_label_index]
data['MAX_YEAR'] = row[max_year_index]
data['CNT_SOA'] = row[cnt_soa_index]
data['FHA_SCDW'] = row[fha_scdw_index]
data['FHA_TSC'] = row[fha_tsc_index]
# If this row links to a recorded habitat feature...
if link in habitats:
# Add this species row to the habitat feature's list of species
habitats[link]['properties']['species'].append(data)
# Write habitats to a line-delimited JSON text file `habitats/features.txt`
with open(os.path.join(BASE_PATH, 'gen/features.txt'), 'a') as habitat_file:
# For each habitat feature...
for habitat in habitats:
# Write the GeoJSON feature on a new line
habitat_file.write(json.dumps(habitats[habitat])+'\n')
Creating vector tiles
We used Mapbox Tippecanoe to convert the GPKG file with appended species information to vector tiles.
# Habitat Polygon Vector Tiles # Read habitat features and convert to vector tiles tippecanoe --read-parallel \ --no-polygon-splitting \ -n "NJ Landscape Project Habitat Areas" -A "INSERT ANCHOR LINK HERE" \ -l "nj-habitat-areas" -z 14 -Z 12 \ -f -o /usr/src/data/nj-habitat-areas.mbtiles \ /usr/src/gen/features.txt
In the case of the habitat dataset, many large polygons extended across tile boundaries. Processing without --no-polygon-splitting resulted in lines, or artifacts, along tile edges. Using the --no-polygon-splitting method removes artifacts along tile boundaries. Note that this does increase the data processing time.
Now we could reference the species information related to each polygon for application features like popups and generating the list of habitat by calling the vector tiles species property.
let species = [];
//parse the species property that was stringified during queryRenderedFeatures
tileFeatures.forEach((feature) => {
if (turf.intersect(APP.areaOfInterest.features[0], feature)) {
let item = JSON.parse(feature.properties.species);
species = species.concat(item);
}
});
Application design
Now you’re ready to use the vector tiles on the web! You can use a tool like Mapbox Studio or CARTO to host and style the vector tiles. If you’re building a custom web app, Leaflet, Mapbox GL JS, or CARTO VL support vector tile rendering.
For this application, we hosted the tilesets on Amazon S3 and used Mapbox GL JS and Turf to build out the app functionality.
There were so many directions we could go with the application design, now that we had easy access to the data. Since this project was primarily focused on defining a data processing workflow and providing a Proof of Concept design, we limited feature development to a few core functions.
Based on previous experience using the dataset, I was familiar with the needs of some of the groups of potential users. Mainly, users would want to look up a property and determine the list of species habitat present. We decided to build out 3 main features:
- Descriptive popup on-click that displays general information about the selected habitat polygon
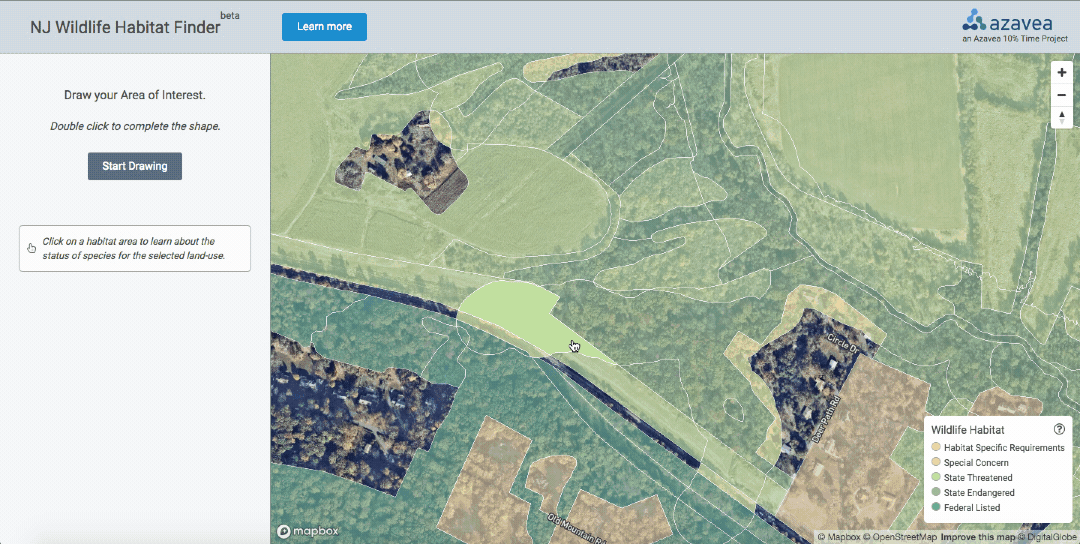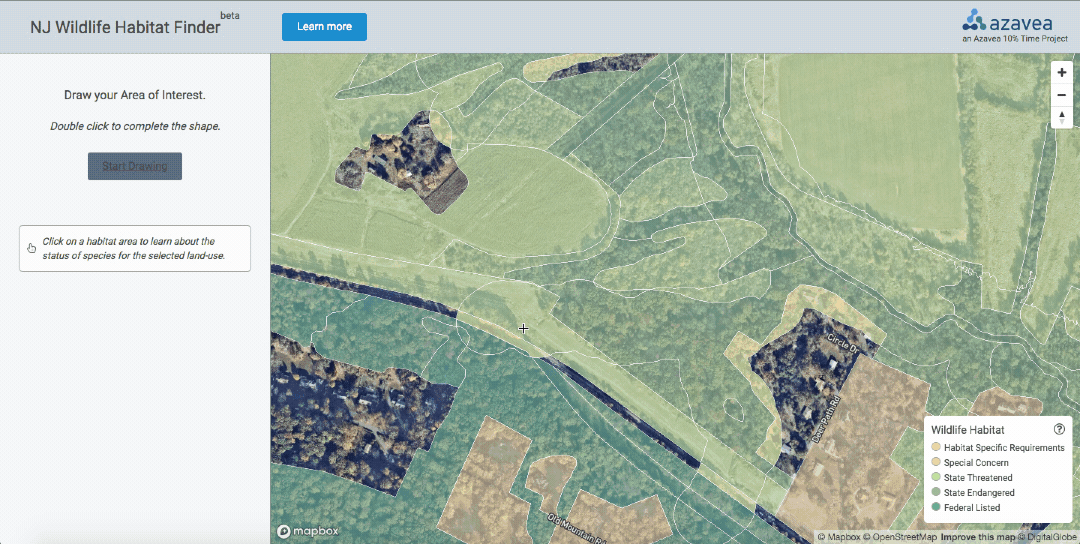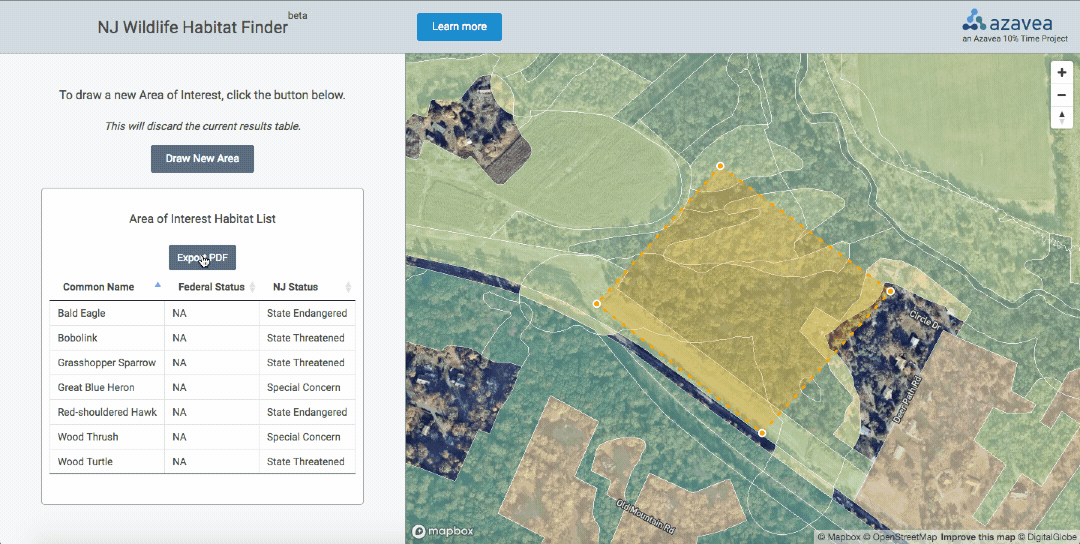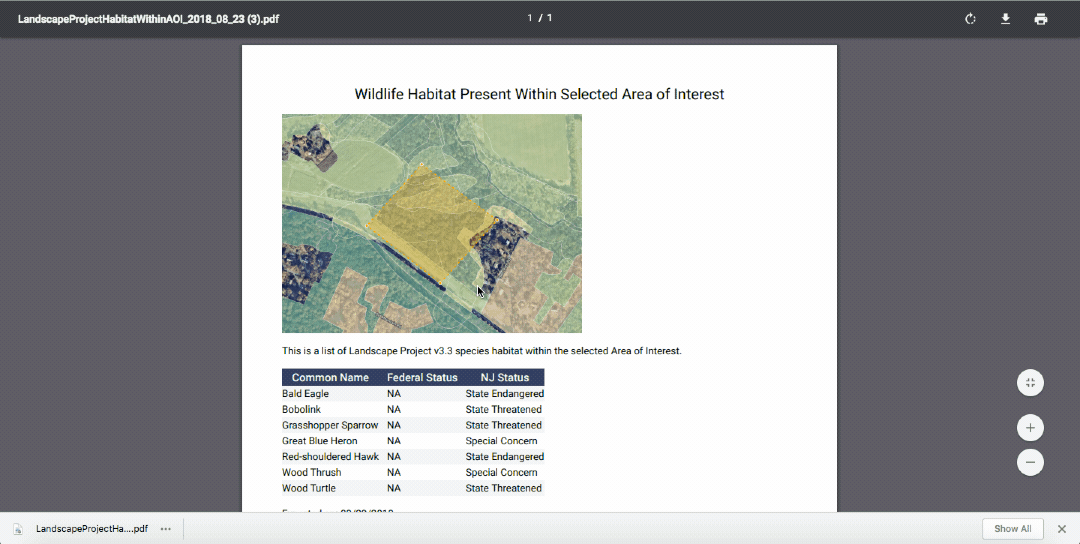
- List wildlife habitat within a custom Area of Interest along with the protection status of each species
- Allow a user to export a PDF of the wildlife habitat list
Accessing the related tabular data
The updateAreaOfInterest function calculates the bounding box of the Area of Interest and stores a list of vector tile features that intersect the Area of Interest as a variable. Then we parse the species property list of JSON objects for each vector tile feature within the Area of Interest and concatenate the species information into one list.
function updateAreaOfInterest() {
APP.areaOfInterest = turf.combine(DRAW.getAll());
if (APP.areaOfInterest.features.length > 0) {
frameMap();
constrainMap();
let bbox = turf.bbox(APP.areaOfInterest.features[0]);
let southWest = [bbox[0], bbox[1]];
let northEast = [bbox[2], bbox[3]];
let northEastPointPixel = MAP.project(northEast);
let southWestPointPixel = MAP.project(southWest);
let tileFeatures = MAP.queryRenderedFeatures([southWestPointPixel, northEastPointPixel], { layers: [ 'nj-habitat-areas' ] });
let species = [];
//parse the species property that was stringified during queryRenderedFeatures
tileFeatures.forEach((feature) => {
if (turf.intersect(APP.areaOfInterest.features[0], feature)) {
let item = JSON.parse(feature.properties.species);
species = species.concat(item);
}
});
APP.featuresOfInterest = species;
updateApp();
} else {
APP.contextFeatures = turf.featureCollection([]);
APP.featuresOfInterest = turf.featureCollection([]);
unconstrainMap();
updateApp();
}
}
Since there is a many-to-one relationship between the species information tables and the vector data features, we needed to be sure to remove duplicates before displaying the list to the user.
We removed duplicate wildlife records by species name and presented the results in the sidebar using the jQuery DataTables plugin.
The jQuery DataTables plugin included export button functionality as an extension. By adding some custom fields and basic styling to the PDF export, we enabled users to download a PDF to attach to their reports, deliver to State agencies by mail, or bring along to a meeting.
Here’s the full DataTables function we used to display the list of wildlife habitat in the sidebar and as a PDF export:
$('#table').DataTable( {
data: uniquesList,
dom: 'Bfrtip',
scrollCollapse: false,
paging: false,
info: false,
compact: true,
searching: false,
responsive: false,
buttons: [
{
extend: 'pdf',
text: 'Export PDF',
className: 'new',
filename: function() {
var today = new Date();
var dd = today.getDate();
var mm = today.getMonth()+1;
var yyyy = today.getFullYear();
if(dd<10) {
dd = '0'+dd
}
if(mm<10) {
mm = '0'+mm
}
today = yyyy + '_' + mm + '_' + dd;
filename = 'LandscapeProjectHabitatWithinAOI_' + today;
return filename;
},
title: 'Wildlife Habitat Present Within Selected Area of Interest',
messageTop: 'This is a list of Landscape Project v3.3 species habitat within the selected Area of Interest.',
messageBottom: function() {
var today = new Date();
var dd = today.getDate();
var mm = today.getMonth() + 1;
var yyyy = today.getFullYear();
if(dd<10) {
dd = '0' + dd
}
if(mm<10) {
mm = '0' + mm
}
today = mm + '/' + dd + '/' + yyyy;
exportDescription = '\n' + 'Exported on: ' + today + '\n \n' + 'Data source: NJDEP Landscape Project Version 3.3 species-based habitat data, 2017' + '\n \n' + 'Created using: https://njwildlife.azavea.com';
return exportDescription;
},
customize: function (doc) {
var img = new Image();
var mapCanvas = MAP.getCanvas(document.querySelector('.mapboxgl-canvas'));
img.src = mapCanvas.toDataURL();
doc.content.splice(1, 0,
{
margin: [0, 0, 0, 12],
alignment: 'left',
width: 300,
image: img.src,
},
);
}
}
],
columns: [
{ data: 'COMNAME', title: 'Common Name' },
{ data: 'FED_STATUS', title: 'Federal Status' },
{ data: 'NJ_STATUS', title: 'NJ Status' }
]
});
}
Note that you can nest functions within DataTables properties to create custom text fields like the current date or image of the current map extent. To learn more about how to save a Mapbox GL web map extent as an image, check out this post.
To create continuity with other public uses of this open dataset, we adopted the NJDEP color palettes that are used to display this data on agency websites and in layer package downloads.
Future possibilities
This application fits a specific need related to land conservation and preservation. But the data processing workflow that converts a geodatabase with related tabular data into vector tiles for use in a web application applies to a variety of use-cases.
The source code for the data processing steps and application is available under an open source license. We hope you’ll leverage the data processing pipeline for work with similar source data formats. Keep us in the loop – let us know what you build!
