
Data doesn’t have any value unless you can use it… and trust it. Users need to quickly access data and know where it came from. This is especially true with the integration of AI, making quick access more achievable but data provenance more opaque. This is where STAC comes in. The reinsurance industry uses climate models from a variety of sources which requires keeping track of where data comes from and how to access it. STAC tracks provenance and access patterns as well as enabling dataset discovery sub-dataset search.
When it comes to responding to climate disasters amidst a flurry of unpredictable conditions, metadata makes it easier to locate and make sense of data. Our discussion in this blog post was inspired by Tee Barr’s recent post about the connection between data and risk management. In the following sections we dive deeper into this idea, providing actionable steps for deploying STAC for reinsurance use cases.
Why climate data analysis needs metadata
As our wise colleague Matt Hanson once said: “It is more important to characterize the data you have than to strive for the data you do not have.”
Metadata stores information that is not explicitly present in data, as well as information distilled from the data.
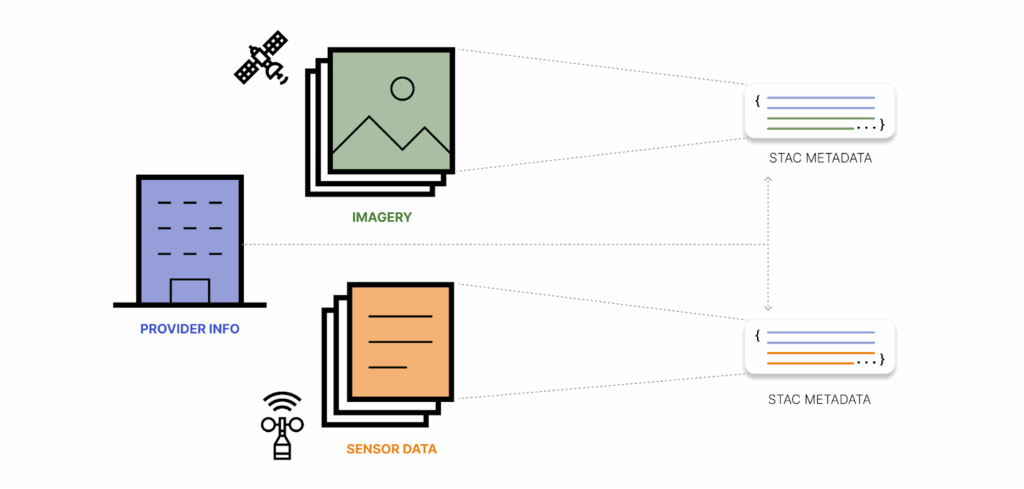
With metadata you can:
- Discover relevant datasets based solely on concepts like “ice”, “hurricane”, “flood” without needing to know the names of specific data products and where to find them.
- Download less data by searching for and directly accessing specific files that have to do with the time and place that you are interested in and meet your constraints.
- Fully reproduce derived datasets based on provenance and applied processing steps.
- Define how systems should operate with your data. Well-structured metadata is AI’s bread and butter – they gobble it up.
When evaluating risk, particularly in the case of compounding risks like climate vulnerabilities, the ability to access specific, relevant information easily and quickly cannot be overstated. Good metadata is the backbone that makes all of this possible. According to Matt Hanson, “Flexibility is the enemy of interoperability.” Good metadata needs a good specification. Enter STAC.
What is STAC?
STAC is a specification for storing metadata as human-readable and machine-readable geojson with a well-defined API. STAC establishes an ecosystem of extensions that define what specific fields mean within STAC metadata. This is a big deal for interoperability since it enables users to find many of the same exact fields on Landsat items that they might find on Sentinel items.
The STAC API specification defines how to dynamically discover datasets of interest and search for the exact files you need using spatiotemporal (eg: last July in Pennsylvania) or property-based constraints (eg: without too many clouds).
This makes it possible to answer complex questions like:
- What was the most destructive day of the 2024 hurricane season in Florida including wind and stormwater surge?
- How did Hurricane Ida affect the salt marshes of Louisiana and how does that impact the climate resilience of in-land communities?
- What is the tornado risk profile of the house and garage at 123 Green St, Kansas 12345?
- How risky is it to reinsure a particular set of policies?
Answering these questions requires pulling together DEM data, hydrologic model output, weather forecasts, information on housing stock and property values, ecological field studies… All of these data products are provided by different agencies, organizations and companies and might get updated over time. So, keeping track of provenance is not only important from a reproducibility standpoint, but also for keeping risk assessments up-to-date. When using these datasets as inputs to downstream models it is also crucial to understand the quality of the data and the geographic area and time interval that is covered by any particular data file. That is what STAC is designed to do!
STAC can capture the metadata for all these diverse data products in the same consistent, readable format while leaving the data itself in place. Often the STAC Catalogs already exist and all you have to do is use it. If the catalog does not exist yet it can be created completely separate from the data itself.
Of course, metadata analysis is possible outside of the STAC ecosystem. That said, with STAC users can immediately start using a set of tools that are already developed and tested. STAC is a vetted entity, and has been adopted by government agencies such as NASA, USGS, and ESA. STAC is also popular among commercial satellite providers and earth data aggregators such as Microsoft Planetary Computer.
How to start using STAC externally
Since so many large data providers already have STAC APIs, you can start using STAC immediately. You can search for STAC catalogs of interest and search them interactively in stac-browser. In this way, you can inspect any public STAC (like the Microsoft Planetary Computer, for example).
Once you have identified a collection of interest, you can interactively search for items that are within your Area of Interest. You can also use the STAC API directly, for instance, to find all the of the Landsat data in August 2025 over Nantucket.
Alternatively, you can search programmatically. For example, using the Python library pystac-client you can do:
from pystac.client import Client
time_range = "2025-08-01/2025-08-31"
bbox = [-70.32, 41.23, -69.91, 41.39]
catalog = Client.open("https://landsatlook.usgs.gov/stac-server")
search = catalog.search(bbox=bbox, datetime=time_range)
items = search.item_collection()Regardless of how you retrieve them, these STAC items can then be used to access the data files themselves (in STAC these are called “assets”). For folks in the reinsurance space wanting to learn more about how STAC could work in your specific use case, we can help evaluate your organization’s potential for “STACification” on a discovery call!
You need STAC: capturing metadata internally
So, lots of large data providers have STAC; does that mean that it’s only suitable for organizations who are distributing large volumes of data to the public? No! Smaller organizations have data too, and managing it can be tedious and chaotic. You can use STAC internally to manage the chaos. One of the benefits of STAC is that STAC metadata is separate from the data itself. That means that it can live in a separate location and have separate access controls. It also means that you can experiment with adding STAC without touching or moving your original data files at all. You can even go through several iterations of how to structure your STAC or you can add and remove metadata as you experiment. None of that will disrupt the workflows of people who are using the data right now.
By using STAC internally, you get to use the same open source tools for inspecting and interacting with your own catalog that you use for the large public catalogs. You don’t need to learn subtly different syntaxes and metadata fields. It’s all STAC.
Once you are in the all-STAC world you can write algorithms that take STAC as their input and output STAC as well. This is a good way of generalizing across multiple data providers.
This is how we manage Earth Search at Element 84. We have STAC in/STAC out pipelines that run on batch/lambdas on AWS and write products into S3.
STAC for risk management in action
As the amount of available data in our world continues to increase at an exponential rate, users face the challenge of sifting through that data to find answers to their questions.
Reinsurers and risk managers are not exempt from this challenge, and that’s especially true when it comes to the rapid response required in the climate-related disaster world. Our team is not new to STAC, but we’re always excited by new potential instances in which STAC can make data more accessible to new users. Over the past several months we’ve been diving into the importance of metadata through discussions around chunking, compression, and the nuances of data formats like zarr and COG, and we’re excited to spotlight real world applications for some of these discussions.
Stay tuned for more of our thoughts in this area during Climate Week 2025 and beyond. Also, if you’re interested in continuing the conversation around metadata, either generally or in the risk management space, we’d love to hear from you.

