About a year ago, I started on a new project at Element 84 working with geospatial imagery. In this blog post, I will document some things I learned on my journey. My hope is these lessons learned will help encourage more generalist software engineers to start experimenting with geospatial data and tooling.
I had never worked with satellite imagery, and like other software engineering efforts I try to set up a local environment for testing. I asked my co-workers where to pull down some data to start looking at it. The first roadblock I hit was the data were quite large, so a local development environment was not always an ideal goal (more on this later). In fact, I learned simply finding where data is hosted can be challenging, then manually or programmatically accessing it through different webapps, portals, and data stores can be challenging as well.
Fortunately, there is a community movement for the latter problem – the Spatio Temporal Asset Catalog STAC, a growing ecosystem and has many advantages for data providers and consumers:
- There are many client tools that facilitate data searching and discovery, such as pystac-client and Open Data Cube
- Because STAC is a common interface, you can run the same client code against any compliant STAC API with little rework, e.g. pull all Landsat-8 and Sentinel-2 data for a given region and date range from two different APIs with the same client code
- It is lightweight, and easily extended with public or custom STAC extensions
STAC is organized into catalogs, and a list of some publicly available catalogs is available here. Catalogs contain one or more collections. Cloud providers, such as AWS and Microsoft, have begun STAC-ifiying large geospatial datasets and making them publicly available, through AWS Public Datasets and Microsoft Planetary Computer. Element 84 is one such provider: we manage the entire Sentinel-2 STAC catalog and make it available through Earth Search. I highly recommend checking it out.
Here is an example using the pystac-client CLI to search for Landsat-8 imagery and Sentinel-2 imagery from two different data providers (Pystac-client installation instructions). Pulling data requires, at a minimum:
- The STAC API endpoint URL
- The collection name
- An area of interest – either a bounding box (bbox) or intersecting polygon geometry
- The time range of when imagery was captured (datetime)
Landsat-8 Collection 2 Level 2 Surface Reflectance Product:
stac-client search --url https://landsatlook.usgs.gov/stac-server -c landsat-c2l2-sr --bbox -75.553837 40.917404 -75.493841 40.951187 --datetime 2021-12-23/2022-01-08
Sentinel-2 Level 2 Cloud Optimized GeoTIFFs (COGs):
stac-client search --url https://earth-search.aws.element84.com/v0 -c sentinel-s2-l2a-cogs --bbox -75.553837 40.917404 -75.493841 40.951187 --datetime 2021-12-23/2022-01-08
Note that the only differences are the URL and collection name.
Glossary of Terms
STAC Concepts
When I was first learning about the STAC ecosystem, I was confused by a lot of similar-looking data types. Here is my greatly oversimplified mental mapping that may help others.
STAC-Server
STAC metadata is typically served over the internet via an API. One commonly-used server application is stac-server, which deploys NodeJS/cloud infrastructure to make geospatial data accessible via the web. Currently the only stac-server backend is elasticsearch, although other backends are planned to be supported in the future. This is deployed by the data provider for public datasets, but you may wish to deploy your own stac-server for public or private use. I have done this when I wish to run an algorithm to change some source data, and publish it to my internal stac-server in a new collection. This way I can continue to leverage the STAC client tooling to collaborate with my team.
Collection
A collection is defined by the STAC spec as a group of individual scenes who share common characteristics, e.g. all Landsat-8 Collection 2 Level 1C imagery. In Elasticsearch, Collections are logically Elasticsearch indexes.
Item (aka Scenes)
A scene contains two important properties: a datetime and a bbox – that is, this is the representation of what a satellite captured at a given location and point in time. In pystac terms, this is an Item object type. When talking to others, I’ve found the most consistent way to communicate is to use the term “scene”, which does not require knowledge of the STAC ecosystem.
Note: pystac and pystac-client are two different repositories.
FeatureCollection
A list of items, the result of a pystac-client query. For example, if I wanted to know what items over an area of Cambodia had < 10% cloud cover, I would make a pystac-client query and get back a FeatureCollection of 0 or more items, depending on whether there was data in that collection available that matched my query.
General Geospatial Concepts
Bbox vs polygon vs geojson
At a higher level, as an earth observation newbie, I was initially tripped up about the relationship between geojson, a polygon, and a bounding box (bbox).
Geojson is the standard for expressing geographical shapes in json format. Geojson contains a ` type` , and one such type is a polygon.
Ref: https://geojson.org/
Polygons are one type of geojson that represent physical areas, e.g. the boundary around the state of Virginia.
Ref: https://geojson.org/geojson-spec.html#polygon
Bounding boxes are rectangles that include four points: bbox = left,bottom,right,topRef: https://wiki.openstreetmap.org/wiki/Bounding_Box
bbox = min Longitude , min Latitude , max Longitude , max Latitude
Here is an example: suppose I was interested in an area around Alexandria, VA. I would draw a polygon, which is a geojson object of type: polygon. The bounding box would be the rectangle that fully contains this polygon.
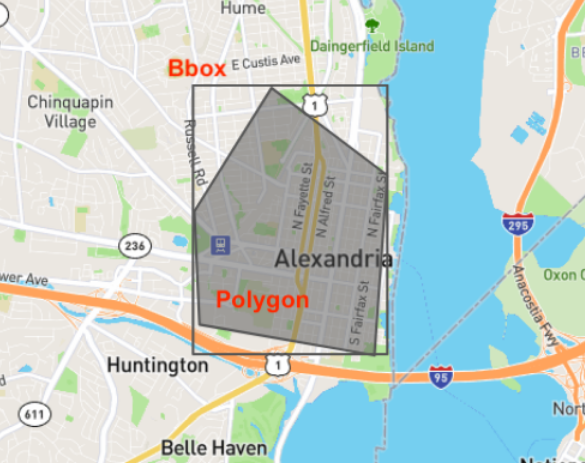
You can use tools like https://geojson.io and https://boundingbox.klokantech.com/ to help identify regions of interest for STAC querying.
When creating a pystac-client query, you can either specify a bbox, or an intersects geojson; both will pull all available data in the collection that has pixels within the bbox or polygon boundaries.
Putting it all together: Searching for data with pystac-client
Pystac-client is a Python CLI and library that facilitates pulling STAC metadata from STAC APIs.
Let’s start with the example we used earlier:
stac-client search --url https://earth-search.aws.element84.com/v0 -c sentinel-s2-l2a-cogs --bbox -75.553837 40.917404 -75.493841 40.951187 --datetime 2021-12-23/2022-01-08
I can also apply filters, for example if I wanted to guarantee that if an image exists in my datetime window that is relatively cloudfree I can append that to the end of my query:
stac-client search --url https://earth-search.aws.element84.com/v0 -c sentinel-s2-l2a-cogs --bbox -75.553837 40.917404 -75.493841 40.951187 --datetime 2021-12-23/2022-01-08 -q "eo:cloud_cover<15"
Note that up until now we’re only working with metadata. Let’s say we would like to pull all of the assets that exist for a given scene.
There are a few ways to do this. You could use the AWS CLI (if the href is an S3 url), programmatically using boto3 or cirrus-lib
from pystac_client import Client
from os import path
from urllib import request
client = Client.open("https://landsatlook.usgs.gov/stac-server")
my_search = client.search(
max_items=1,
collections=['landsat-c2l2-sr'],
bbox=[-75.553837, 40.917404, -75.493841, 40.951187]
)
for item in my_search.items():
for asset in item.assets.values():
resp = request.urlretrieve(asset.href, path.basename(asset.href))
Some other quick tips using STAC APIs
Quick tip #1: defining a datetime
For satellites in orbit, there is a revisit rate for how frequently an area of interest will be captured. For example, if searching Landsat-8 data, the revisit rate is 16 days, so to ensure at least one capture we provide a date range -8/+8 the desired date. To guarantee a Landsat image closest to my desired date December 31st, my datetime range for my STAC query would be: 2021-12-23/2022-01-08.
Quick tip #2: Authentication
There are multiple reasons why data providers protect their data with authentication. Some STAC APIs are requester-pays S3 buckets, others require an Authorization header, or https signed urls that don’t require an account. They might collect metrics on who is accessing the data. Data providers pay for the storage of imagery in the cloud, and may also be concerned with data egress.
If you’re trying to pull data (not metadata) and are seeing 403 Forbidden or other authentication errors, you may be missing the auth part of your client connection.
What’s next?
This post is an initial introduction to discovering and pulling data using STAC APIs. It’s helpful for an algorithm developer, scientist, or researcher who wants to pull a large amount of filtered data to a local drive for analysis. However, this only scratches the surface; the true power of STAC is that it changes how we are able to work with large geospatial data sets.
Some algorithms that would traditionally require data to be available locally are able to be replaced with STAC client tools. For example, I would not need to pull a 1.4G image to see if it was cloudy; this information is available in the metadata. Open Data Cube allows us to create virtual data cubes for time series analysis.
Current best practices not only reduce the reliance on local storage but also the compute layer. Tools like dask and jupyterhub work nicely in this ecosystem and allow on-demand, cloud-scale processing that spins down to zero when not in use. It can allow for secure collaboration between researchers.
We need to make cloud computing more accessible to our scientists. One of the best feelings I’ve had as a software engineer is working with a world-class researcher who was never able to run his algorithm on a GPU because it was cost prohibitive for his university. I was able to provision a GPU EC2 instance, and he can fine tune his algorithm and know exactly what his resource requirements are that he would need to request. Also, now he has some AWS skills and may not even need his university to purchase hardware!
If this sounds interesting, let’s start up a discussion on Twitter! You can reach me @danstarkdevops and our talented team @Element84.
