At the heart of every machine learning model is its training data. Some have learned this lesson the hard way. In 2016, Microsoft released it’s chatbot “Tay” into the wilds of Twitter to learn how to converse. Targeted by trolls who inundated the bot with hate speech, Tay soon “learned” enough to make pronouncements such as “Ricky Gervais learned totalitarianism from Adolf Hitler, the inventor of atheism.”

While users of Earth observation data may not find themselves battling 4chan, well-labeled training images are still key to the quality of any algorithm built upon them. Members of the Raster Foundry, Raster Vision, and R&D teams at Azavea have long been at the forefront of AI and satellite imagery. In recent months, we’ve further honed our expertise while developing our own labeling tool, GroundWork, for public release.
I’ve also spent the last year or so overseeing labeling efforts for some of Azavea’s machine learning projects. I’ve learned a lot while creating documentation and training materials for annotators, software engineers, and project managers. In the following blog, I’ll discuss the common ways of labeling satellite imagery for machine learning and what we’ve learned about each.
Image classification
Image classification is identifying an entire image as belonging to one or more classes. Images that are quite large can be broken down into “chips” for classification purposes. You may be most familiar with image classification as CAPTCHA challenges asking you to “Select all the images with cars in them.” Without knowing it, you’ve probably contributed to the labeling of a machine learning dataset.

Applications of image classification
Models trained on image classification have been used to:
- identify nearly 1.5 million solar panels across the continental U.S (the resulting DeepSolar database is freely available)
- predict a neighborhood’s political leanings based on the type of cars parked in it
- improve the forecasting of space weather
Labeler’s tip: Remove irrelevant imagery with a determinant class
If you need more than two classes or know a number of images in your dataset are not useful for your model, consider having a determinant class. Assigning an image to a determinant class prevents any further classification.
For example, if your project considers land features, but your imagery contains a number of coastline shots, a determinant class of “Water” tells your labeling tool that no other class (i.e. land features) will be selected. This allows annotators to essentially “reject” irrelevant imagery.
Object detection
Object detection combines two labeling methods: object localization and image classification. When labeling an image for object detection, you draw a bounding box around one or more objects (localization) and assign it/them one of a predetermined set of categories (classification).

Applications of object detection
Models trained on object detection have been used to:
- lead the fight against schistosomiasis in Senegal
- develop a “smart” camera that uses machine learning to send an alert when a gun or other weapon appears on screen
- deter neighborhood cats from wandering onto your lawn (!)
Object counting
Object counting is one of the most common ways to use an object detection model. A newsroom might use object counting to estimate the size of a crowd at a protest, while a retailer may use a similar model to predict the hours with the highest level of foot or car traffic. Investors in retail markets have already gotten savvy to this technique for tracking and predicting sales. Other uses of object detection models include detecting and monitoring elephant populations and identifying new housing to aid the 2020 U.S. census.
Labeler’s tip: Define your classes
Define your classes early and exhaustively. If you’re mapping vehicles, do you want to differentiate between cars, vans, and flat-beds? Or, do you want to consider them all “passenger vehicles”? If so, what exactly delineates a “passenger vehicle” from a “cargo vehicle”?
You’ll want to think this through as much as possible before labeling your imagery. Edge cases will inevitably come up–but the more you plan ahead the better prepared you and your team will be.
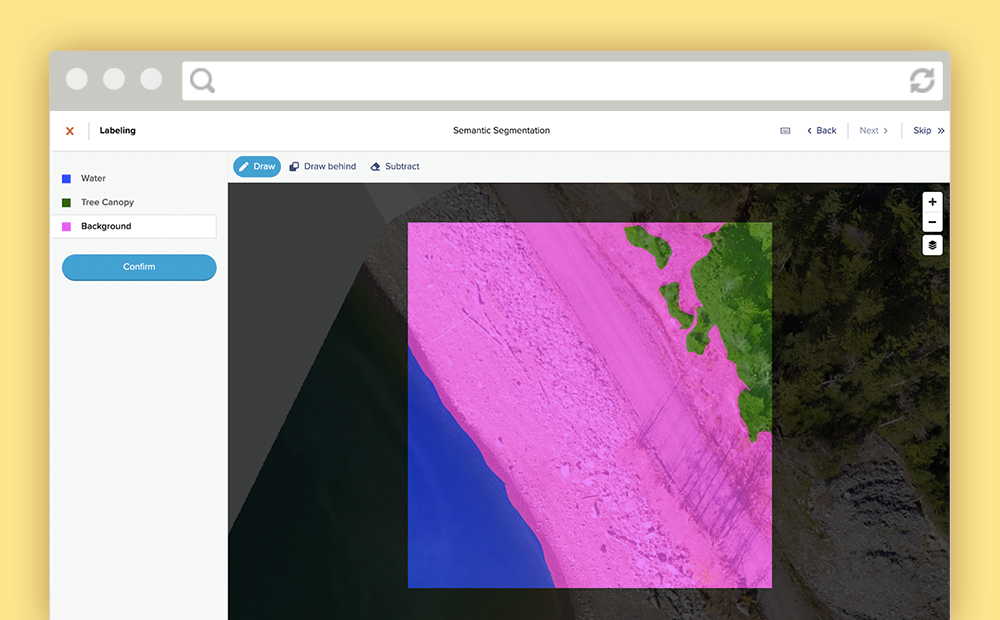
Semantic segmentation
In semantic segmentation, each pixel of an image is classified as belonging to one of a set of classes. Image classification allows you to say whether an image contains a car or not. Object detection allows you to localize that car by creating a bounding box around it. Semantic segmentation allows you to localize and classify every pixel of the image that contains any portion of a car. You’ll also localize and classify every other class present in the image pixel by pixel.
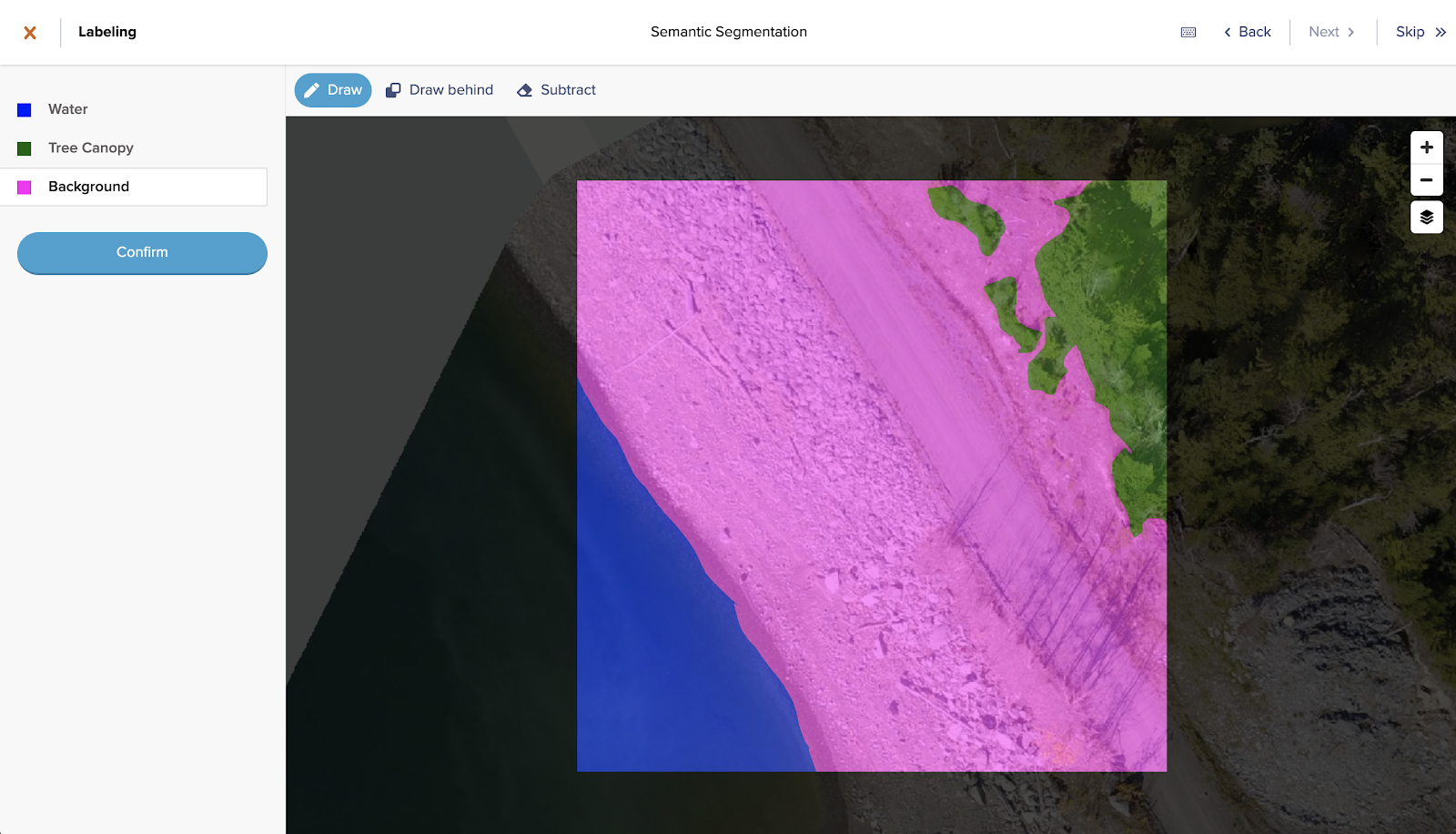
Applications of semantic segmentation
Semantic segmentation is ripe with potential applications from determining the best time to pick strawberries to identifying cancerous cells. It can even help improve the quality of your cell phone photos. Models trained on semantic segmentation have also been used to:
- Predict road networks in satellite imagery
- Estimate the solar capabilities of entire cities
- Create a precise land cover map of the Chesapeake Bay watershed
Label “noise” and semantic segmentation
While training a semantic segmentation model to detect buildings in satellite imagery, engineers at Azavea ran experiments to see how “label noise” affected the quality of the model’s predictions. Label noise generally refers to erroneous labels. Our results, though limited, indicate that while datasets with errors can produce decent results, too many will reduce a model’s accuracy.
Labeler’s tip: Use a fill tool
A fill or paintbucket tool is an annotator’s best friend in semantic segmentation projects. Imagine carefully drawing a polygon around the imprecise contours of a river in the center of an image, only to have to redraw the same boundaries again when classifying the remaining parts of the task. The ability to fill large areas of the unlabeled portion of a task (without losing your existing labels!) is crucial.
Instance segmentation
When labeling for instance segmentation, the annotator draws a polygon around each instance of an object in an image. As in object detection, a particular object is localized and classified. And, like semantic segmentation, each pixel of an object is classified.
The major difference between semantic segmentation and instance segmentation is that the latter allows you to classify each instance of an object in an image as a separate entity. Using semantic segmentation, two cars adjacent to each other in image would be classified together as “Car”. Instance segmentation allows you to keep every instance of a car in an image separate, i.e. two adjacent cars would be “Car A” and “Car B.”

Applications of instance segmentation
One major use of instance segmentation is automated feature extraction, particularly of building footprints. Models trained on instance segmentation have also been used to:
- automate the rotoscoping powering visual effects in film
- bring advanced photo editing to smartphones
- trace the individual neurons in the brain of a fruit fly
Labeler’s tip: Choose contrasting colors
Choose label colors that contrast with your imagery. While it’s intuitive to make the class called “Body of Water” blue, if your label will appear as you draw it, making it and the object the same color will cause issues for your annotator. While the finished task may take a bit more work to visually interpret, distinct colors will save your labelers from many headaches–squinting at a screen for hours can take its toll.
Making meaning of satellite imagery
Between our machine learning tools and resources, partnerships, and our soon to be released annotation tool, Azavea is working to solve the challenges of data labeling for the machine learning workflow. Let us know how we can work with you to make meaning of your Earth observation data.
