
The ability to sift through the vast amounts of imagery that satellites collect remains one of the primary challenges of the geospatial industry–a challenge that only grows harder as the number of imaging satellites in orbit continues to go up. Traditional supervised machine learning allows us to train specialized models that can detect specific objects such as buildings, cars, and trees, but this very specialization limits their usefulness. In this age of generalist foundation models, it is only natural to dream of a single foundation model that understands both Earth imagery and natural language, and can handle arbitrarily complex queries. Thanks to recent advances in vision-language models (VLMs)–more specifically, remote sensing VLMs–that dream is solidly within reach.
In this blog post, we take a close look at two such remarkable VLMs that have come out in the past few months: SkyCLIP [1] and RemoteCLIP [2], both of which make their code, datasets, and model weights publicly available. Using these models, we demonstrate a “queryable Earth” functionality that allows retrieving images along with their geolocations using text queries over a large geographical area.
What is a vision-language model?
While the nomenclature hasn’t fully crystallized yet, for the purposes of this blog, we define a vision-language model (VLM) broadly as any foundation model that can encode both images and text to the same embedding space. More plainly, the vector embedding that the model produces for a satellite image of a house with a swimming pool should be similar to the embedding it produces for the text “a satellite image of a house with a swimming pool”. For a deep dive into vector embeddings, see our previous blog post.
The seminal work in this area was OpenAI’s Contrastive Language-Image Pre-training (CLIP) model [3], trained on a humongous dataset of 400 million image-text pairs scraped from the internet, which was introduced in 2021 and has powered all iterations of the DALL-E image generation tool [4, 5, 6] since. This not-so-open OpenAI work was eventually actually opened up to the public by the OpenCLIP project [7] and has since then been widely used for creating fine-tuned CLIP models for specific domains such as medical and, more relevantly, geospatial imagery.
This fine-tuning is important because although a general CLIP model would have seen all kinds of images during training (the OpenCLIP models having been trained on as many as 2 billion image-text pairs!), including satellite and aerial images, these would have only been a tiny fraction of the satellite imagery held in various collections. Moreover, it is not likely that the text accompanying these images would have been very descriptive or very high quality (this is a general problem with the CLIP dataset and discussed in more detail in [6]).
Vision-language models for remote sensing
The main challenge, then, for creating VLMs for remote sensing is coming up with high-quality and descriptive image captions for satellite and aerial imagery. Both RemoteCLIP [2] and SkyCLIP [1] take very creative but distinct approaches to solving this problem.
RemoteCLIP takes existing datasets with object detection and semantic segmentation labels and heuristically converts them to natural language captions, such that, for instance, an image from an airplane-detection dataset with a bounding box near the center yields the caption “An airplane in the middle of the picture.” These generated captions are combined with other existing image-text datasets to produce a training dataset of around 800K image-text pairs.
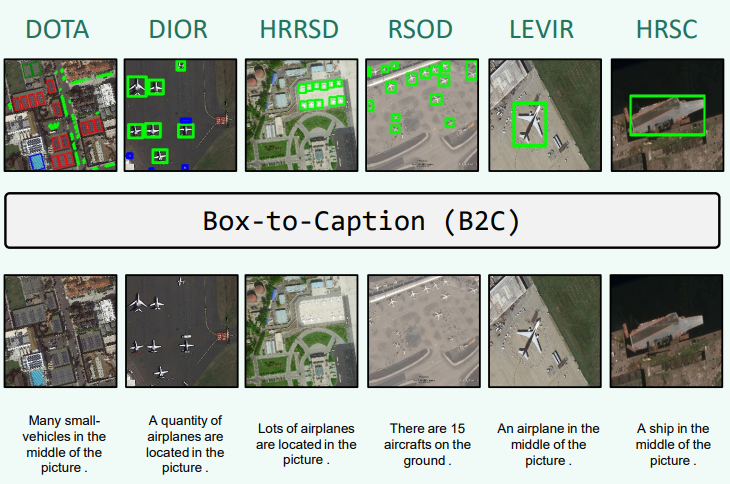
SkyCLIP, on the other hand, takes a similar but more scalable approach of heuristically generating textual captions from OpenStreetMap semantic tags. These are very cleverly filtered, in an automated way, based on whether they represent visual features and whether they can, in fact, be seen at the resolution of the corresponding image. The result is the SkyScript dataset with 2.6 million image-text pairs covering 29K distinct semantic tags.

Lastly, although not investigated in this work, a similar effort is the GeoRSCLIP model and the corresponding RS5M dataset [8]. Instead of new captions, this dataset is composed of remote sensing image-text pairs extracted from existing large-scale general image-text datasets.
Querying at scale
So how do we use these models to make imagery queryable with natural language? Answer: similarity searches on vector embeddings. We simply chip the area-of-interest (which should eventually include the whole Earth), create image embeddings for these chips using a VLM, and store these embeddings in a vector database or some other format. At search-time, the user’s natural language query is converted to a vector embedding using the same VLM, and compared against the stored embeddings to find the closest matches.
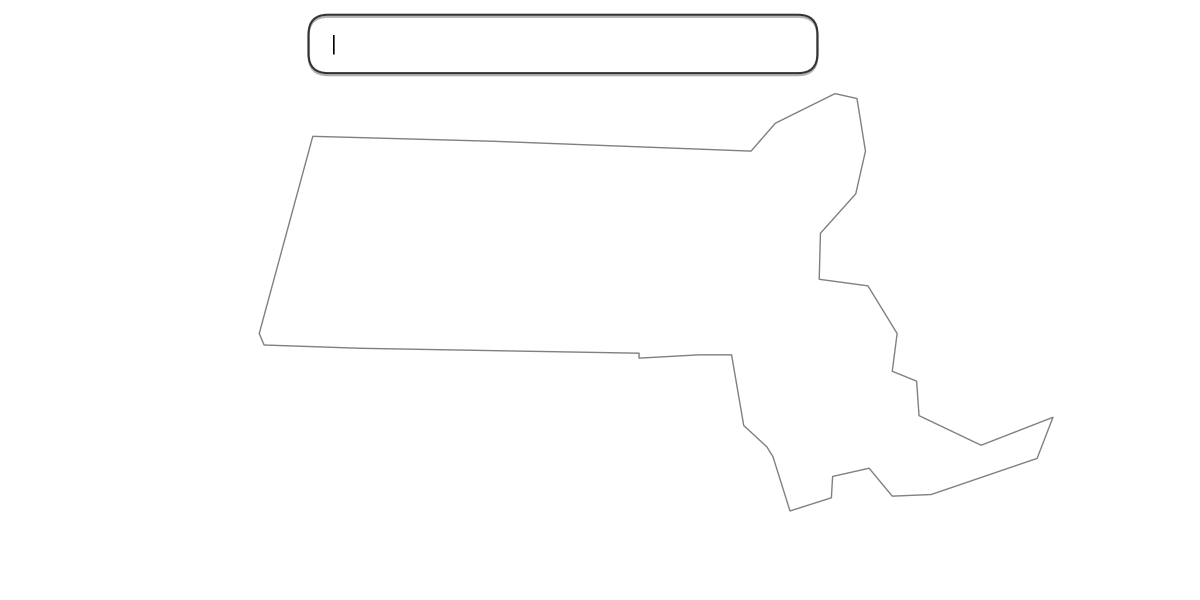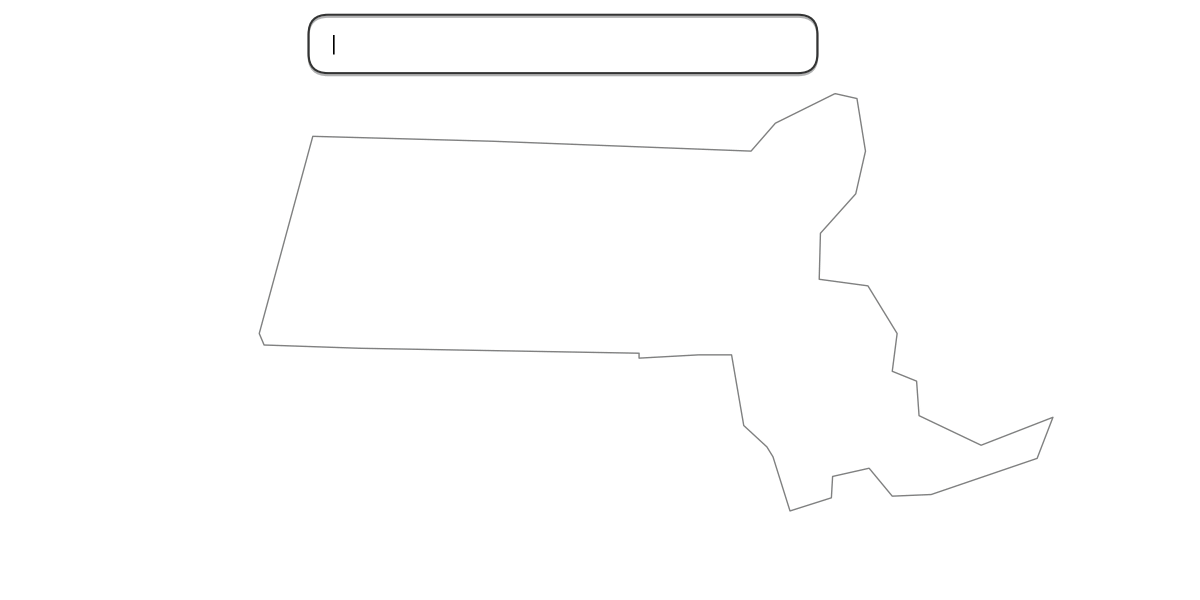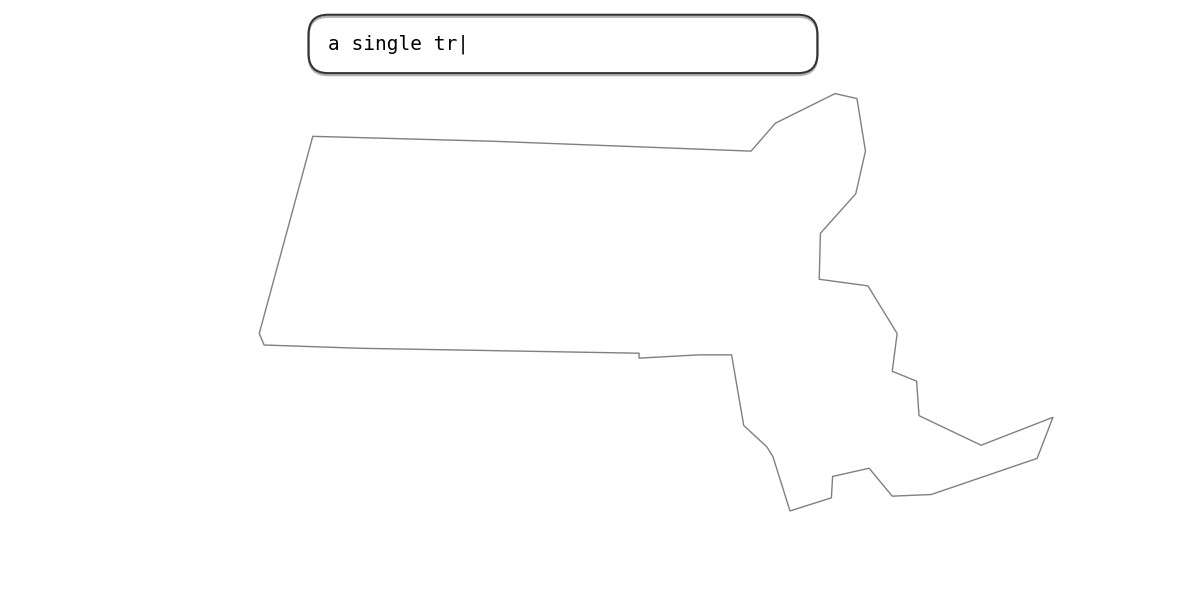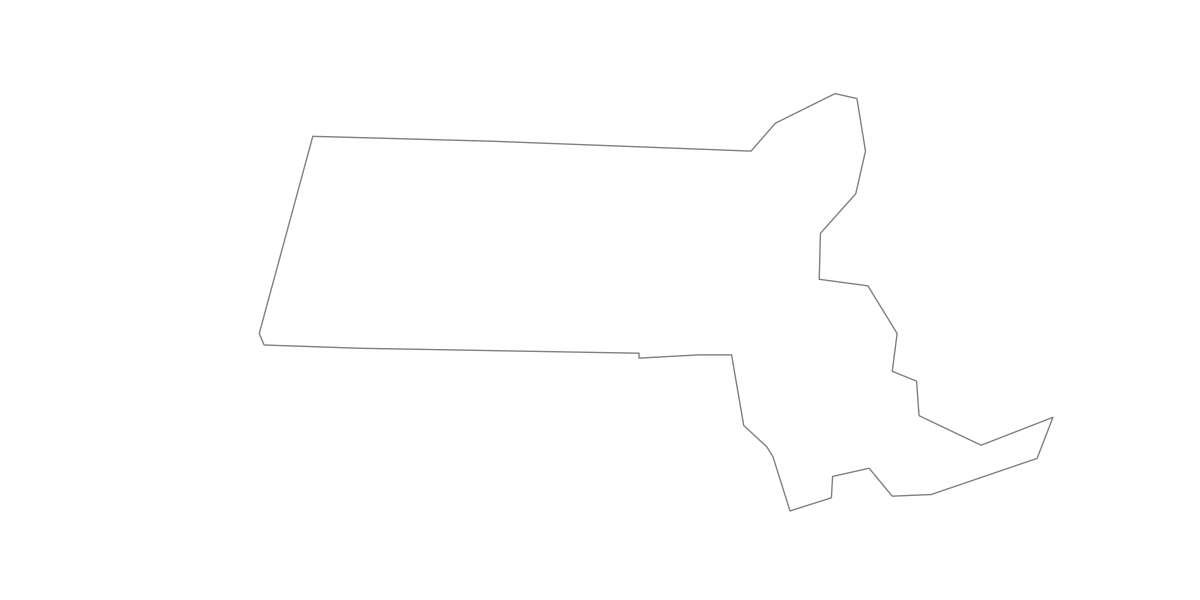
The power and utility of this approach is best appreciated when it is applied at scale to a large geographical area. The visualization below shows a demonstration of this approach applied to NAIP imagery over the entire state of Massachusetts. We can see that we get excellent matches for even complex queries such as “a single tree in an empty field”.
Robustness to resolution
Both SkyCLIP and RemoteCLIP show strong robustness to varying resolutions, easily handling both Sentinel-2 as well as NAIP imagery. This is not particularly surprising given both of their training datasets include a good mix of different resolutions, but still very encouraging news since it means that we will not need to have a different VLM for each satellite.

An important parameter when building such a search capability is the chip size. Both models seem to work well at different chip sizes. Below, we see some top SkyCLIP matches for the same query at different chip sizes.

Counting objects
If the above wasn’t impressive enough, RemoteCLIP also boasts a remarkable, though imperfect, ability to count objects, as seen in the next figure.

Final thoughts and predictions
These are exciting times in the world of AI/ML research, to put it mildly. As impressive as the above results may seem, we should also keep in mind that these are merely the first attempts at solving this problem, and the models will undoubtedly become more capable with time.
The most obvious way to improve these models would be through higher-quality captions. The ideal solution would be to have these created by actual humans, but this approach is cost-prohibitive and hard to scale, which is what motivates the current heuristics-based approaches. It also means that there is a lot of room for improvement. In this context, the DALL-E 3 approach of bootstrapping a better captioning model is interesting.
Another axis for improvement, especially relevant to geospatial imagery, is supporting non-RGB bands. If we can take an arbitrary window anywhere on Earth and generate a caption using OpenStreetMap tags, as SkyScript demonstrates, then there is no reason why we cannot build up an image-text dataset for any sensor.
Lastly, it would not be in keeping with the times to not talk about generative AI and LLMs in some capacity. Though slightly outside the scope of this blog post, there have been notable efforts, such as RSGPT [9] (among others), to create vision-language chat agents for remote sensing. These chat agents specialize in answering targeted questions about the specific contents of a single image. The basic recipe for building one involves stitching together a pre-trained VLM and a pre-trained LLM and fine-tuning on an instruction-tuning dataset using techniques such as LLaVA [10] (among others).
Get in touch!
As we wrap up, we’d love to hear what our readers think about the concepts covered in this post. Are you interested in seeing a natural language search functionality implemented for remote sensing imagery? What are some search terms that you would like to try? Have you experimented with any vision language models? What limitations have you noticed?
At Element 84, we’re working towards scaling these VLMs to large catalogs of global data with deep time series. If you’re interested in how VLMs can apply to your private data catalog, or if you have any takeaways from this post that you’d like to share, get in touch with us to talk more.
References
[1] Wang, Zhecheng, Rajanie Prabha, Tianyuan Huang, Jiajun Wu, and Ram Rajagopal. “Skyscript: A large and semantically diverse vision-language dataset for remote sensing.” arXiv preprint arXiv:2312.12856 (2023).
[2] Liu, Fan, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, and Jun Zhou. “RemoteCLIP: A Vision Language Foundation Model for Remote Sensing.” arXiv preprint arXiv:2306.11029 (2023).
[3] Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry et al. “Learning transferable visual models from natural language supervision.” In International conference on machine learning, pp. 8748-8763. PMLR, 2021.
[4] Ramesh, Aditya, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. “Zero-shot text-to-image generation.” In International Conference on Machine Learning, pp. 8821-8831. PMLR, 2021.
[5] Ramesh, Aditya, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. “Hierarchical text-conditional image generation with clip latents.” arXiv preprint arXiv:2204.06125 1, no. 2 (2022): 3.
[6] Betker, James, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang et al. “Improving image generation with better captions.” Computer Science. https://cdn.openai.com/papers/dall-e-3. pdf 2, no. 3 (2023): 8.
[7] Cherti, Mehdi, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. “Reproducible scaling laws for contrastive language-image learning.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2818-2829. 2023.
[8] Zhang, Zilun, Tiancheng Zhao, Yulong Guo, and Jianwei Yin. “Rs5m: A large scale vision-language dataset for remote sensing vision-language foundation model.” arXiv preprint arXiv:2306.11300 (2023).
[9] Hu, Yuan, Jianlong Yuan, Congcong Wen, Xiaonan Lu, and Xiang Li. “Rsgpt: A remote sensing vision language model and benchmark.” arXiv preprint arXiv:2307.15266 (2023).
[10] Liu, Haotian, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. “Visual instruction tuning.” Advances in neural information processing systems 36 (2024).
