
When STAC 1.0 was released in May 2021, it already had a foundational ecosystem of software tooling, as well as significant adoption across government and commercial organizations. But, with this strong start, how did STAC start? And why did it become so well adopted? Nearly 5 years ago, the first STAC sprint took place inside the Boulder Marriott, attended by a small group of open source advocates. In this 2-part retrospective, weвҖҷll dive into the history of STAC through my vantage point (part 1), and uncover what makes STAC successful (part 2).
The beginning of Cloud-Native Geospatial
In 2015, Planet converted the Landsat archive into Cloud-Optimized GeoTIFF (COG) and made them publicly available as Open Data on AWS. In 2017 I worked for Development Seed, where we were interested in democratizing access to remote sensing data. Large geospatial datasets were just being made available in the cloud, and Cloud-Optimized GeoTiff was getting established as a format for providing direct and fast access to data on remote file servers.
At this time, Development Seed developed a Python utility called landsat-util. Landsat-util provided a convenient command line tool to easily perform spatial and temporal searches against this data. Users could search for an area and time to download just the spectral bands of Landsat they wanted, or they could use the data file URLs to perform partial remote reads, greatly reducing the time to access.

Landsat-util relied on an external service: Development SeedвҖҷs sat-api, an AWS serverless application that indexed all the Landsat-8 archive metadata. Shortly thereafter, it was extended to index the Sentinel-2 public dataset, and sat-search (later replaced by pystac-client) was created as a client library to search Landsat and Sentinel data.
Although we had an index of both Landsat-8 and Sentinel-2, there was no standard method used to represent the native metadata–each satellite platform had its own unique metadata set. Other than searching by geographic area and time, there was no common way to represent data file locations or useful metadata like cloud cover. In the same way that Development Seed implemented sat-api, other organizations and companies developed their own bespoke data lake implementations. NASAвҖҷs development of the Common Metadata Repository operated along a similar vein and implemented several different metadata formats, but still suffered from critical inconsistencies between different collections.
This lack of a standard meant that every datasetвҖҷs metadata had its own peculiarities, and often customized software for working with it. While GDAL made it possible to work with this variety of geospatial data file formats, the metadata was still unique. There was no single software tool to be able to search and access the data, ultimately placing the burden on the data user.
State of the Map; Boulder, 2017
During the summer of 2017, Chris Holmes reached out to get Development Seed involved in a working group following State of the Map. Chris knew about our work with sat-api, landsat-util, and our interest in aligning metadata (see some early spec discussions here). Led by Chris and funded by Radiant Earth, a group was formed to discuss geospatial interoperability. In addition to Development Seed, 13 other organizations, including Element 84, participated in the sprint. From the start, this was designed to be different from existing standards and focused on users finding and accessing the data, especially in a cloud environment. STAC was not yet a name, it was simply called the вҖңimagery metadata specвҖқ.
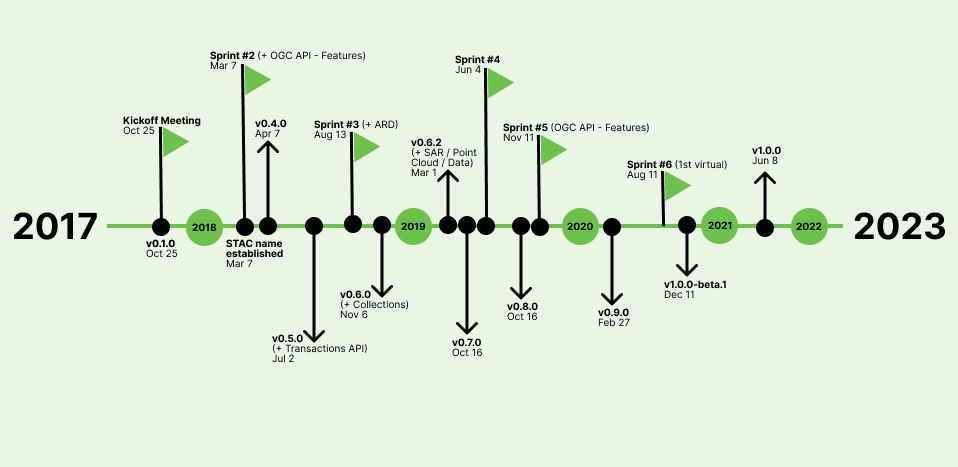
The two-day sprint occurred October 25-27, 2017. Participants gave a series of lightning talks where they shared current, relevant geospatial data efforts. This allowed all of us to establish some common ground. From there, we broke into 4 вҖҳworkstreamsвҖҷ to discuss different aspects of what was needed to create a common imagery specification. These included: core metadata, static crawlable catalog, API, and extensions. By the end of the sprint we had an initial STAC National Agriculture Imagery Program(NAIP) catalog built (thanks to Rob Emanuelle and Seth Fitzsimmons), as well as a basic server implementation. It was inspiring to see the ideas get put into action so quickly.
In-person Sprints (2017-2019)
Through 2018 and 2019 there were a series of in-person sprints that enabled group discussions that are difficult to replicate in a virtual world. In between sprints, the ecosystem was being built up by various contributors – API server implementations (staccato, sat-api, franklin), the start of stac-browser, sat-search, a QGIS plugin, among many others. But, more importantly, there were data catalogs being built. The Landsat and Sentinel public datasets on AWS were made available, USGS made the latest Landsat data available via a STAC API, and companies were starting to use STAC internally for managing large data lakes.
We held Sprint #2 (and #5) jointly with the OGC API – Features effort in order to align a STAC API (so far we had mostly been concerned with static metadata). The fit seemed natural – STAC Collections were represented by OGC API Collections, and STAC Items were GeoJSON Features.
During this time, the openEO project was also underway, funded by the European Commission. OpenEO is a specification for processing earth observation data, which had similar needs as STAC. Luckily, an openEO developer, Matthias Mohr, reached out and became a major contributor to STAC which continues to this day.
Just before Sprint #4 in 2019, I joined Element 84, and continued to support STAC as an important component of supporting large scale, reproducible, geospatial science. We deployed Earth Search, a STAC API for Sentinel-2 Cloud-Optimized GeoTIFFs, developed CMR-STAC, and contributed to the development of the STAC specifications and several projects in the STAC ecosystem.
Contributors and Sponsors
STAC would not have been possible without its many sponsors and contributors. Planet not only supported Chris Holmes for this effort, they were involved at every sprint, hosted Sprint #4, and were main sponsors throughout its development. More recently, Microsoft, in creating the Planetary Computer, has been a major funder of the STAC ecosystem, providing resources to build and maintain PySTAC, pystac-client, stac-fastapi, and stactools.
Similarly, STAC would not have come to fruition without all of its many contributors over the years. The STAC specs and the open-source ecosystem have very much been a community effort. While there were the regulars at most sprints, each sprint brought with it a different set of participants, users who helped expand the community and build tools for real-world use cases. Contributors brought back STAC to their communities and we started seeing early adopters using the tools and catalogs for their own uses. This was an important factor leading to the success of STAC, which I will discuss more in part 2.

STAC 1.0
When the COVID pandemic hit we were just releasing STAC 0.9, which looked a lot like the spec does today, and starting to talk of what was needed for a 1.0 release. The spec, while largely felt complete, needed a lot of wordsmithing and cleaning up. Additionally, we wanted to release STAC as a metadata specification, but the STAC API piece was aligned with OGC API – Features which was still under development. To release a stable core but allow the API to continue development, we split STAC into two different specifications: stac-spec, and stac-api-spec.
It took just over a year to finally release stac-spec 1.0, with one (virtual) sprint. While the lack of dedicated face-time slowed progress, we also wanted to let a STAC release candidate alone for a while, making sure we had any potential changes in. We also wanted time for the community to continue to build up the ecosystem, and build catalogs. Matthias built STAC Index, which is a great resource for newcomers. As of this writing, stac-api-spec is on 1.0.0-rc.2, with a final release in the near future.
Looking Back
Before STAC, there was no consistent way geospatial data was distributed. Different agencies like NASA and USGS had their own metadata formats, often varying between different sensors, and their own tools for searching and working with the data. Existing satellite companies and the burgeoning small sat industry developed bespoke APIs and data portals. Working with data was a chore for users who needed to dedicate a significant portion of every project on data wrangling.
With the user-centric STAC specification and open-source ecosystem a lot of these pre-work tasks have become standardized. Combined with cloud-native data formats, STAC has become a critical piece of the cloud-native geospatial paradigm. It’s used to power exploitation of large data lakes, such as with the Microsoft Planetary Computer. In the second post of this series, I will expand more on why I think STAC has been successful, and what weвҖҷve learned from the project so far.
