
Our team at Element 84 is excited about AI’s potential to help in building systems, understanding the impacts of climate change, and generally helping users access data. At the same time, we’re also concerned with the environmental impact of using this technology. Hugging Face sums up the issue well in their AI Environment Primer:
Artificial intelligence (AI) has an environmental cost. Beginning with the extraction of raw materials and the manufacturing of AI infrastructure, and culminating in real-time interactions with users, every aspect of the AI lifecycle consumes natural resources – energy, water, and minerals – and releases greenhouse gases. The amount of energy needed to power AI now outpaces what renewable energy sources can provide, and the rapidly increasing usage of AI portends significant environmental consequences.
Energy and water consumption has increased with the rise of AI, particularly due to the demands of large language models. GPUs consume more energy than CPUs and generate heat that requires liquid cooling. This increases the amount of water being used by data centers which is particularly concerning amidst a global freshwater scarcity. A study on AI-related water consumption reports that for every 10-50 GPT-3 responses, 500ml of water are consumed. Training and using AI models increases data center usage and thus increases the energy demands. Microsoft recently invested in re-opening the Three Mile Island nuclear power plant to produce the energy needed for its AI development, which concretely represents the huge power demand necessary for AI training.
What can we do about the environmental impact of AI?
As a small company composed of individual AI users and developers we probably won’t be able to change the direction of large companies like Meta, OpenAI, or Anthropic. However, we can take measures to use AI in a sustainable way as we develop solutions that use generative AI. We’ll outline measures that application builders can take to minimize the environmental impact of their AI use. At Element 84, we work under the value “Our work benefits our world” and to adhere to this value we are striving to minimize our environmental impact.
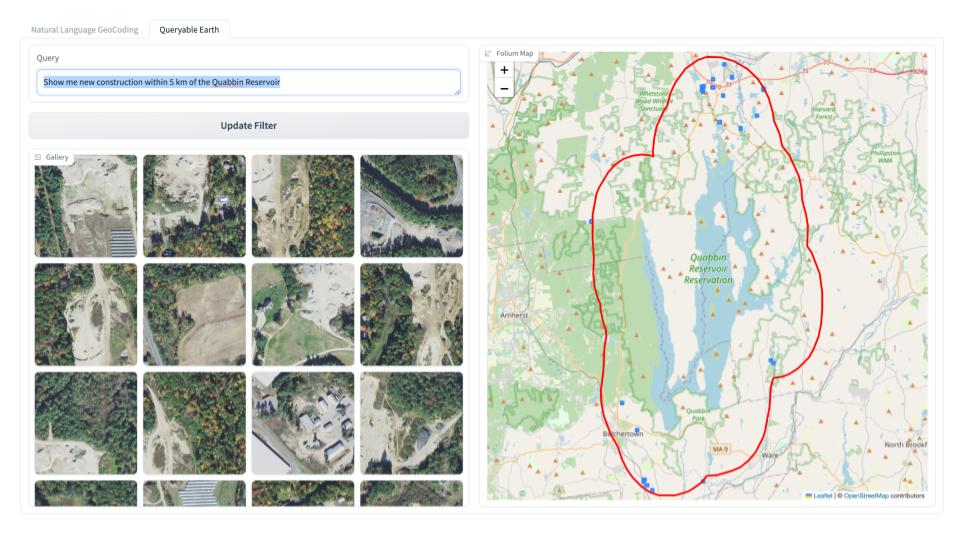
Is AI the right solution?
The first step in creating sustainable solutions is carefully framing the problem and understanding what AI brings to the table. Before jumping into AI, it’s essential to ask: Is this really a problem that requires AI? Not every challenge demands AI; sometimes, traditional software development or even simpler algorithms can achieve the same results with far less energy and computational intensity. By evaluating whether AI is genuinely necessary, you can avoid the unnecessary resource consumption that can come with AI.
Use Pre-trained models
The rise of foundation models means there are tons of pre-trained models to use, likely eliminating the need to train your own model, which is an expensive (computationally and financially) and time consuming task. By using a model that has been pre-trained you are eliminating the impact of the energy and water consumption needed to train a model, in addition to saving money. It also means you may not need to run the model yourself which has the benefits as described in the section on managed services later in this post.
Generally speaking, a pre-trained model is usually the best choice. Techniques such as prompt engineering, agents, and retrieval augmented generation (RAG) are very effective at applying existing models to your own needs.
What about fine tuning? Fine tuning is generally unnecessary given the customization techniques discussed above. Fine-tuning is resource-intensive, both in terms of cost and energy consumption, so we suggest reserving it for scenarios where other methods don’t meet your requirements. While fine-tuning allows you to bypass the initial training phase, you still need to manage and operate the model yourself, missing out on the advantages of fully managed services (explained below).
Use Managed Services
Managed Services, in the context of AI, are cloud services that give you access to on demand use of models without having to run the underlying infrastructure yourself. These include Amazon Bedrock, Google Vertex AI, and Microsoft Azure Cognitive Service. Not only is this much easier for you as a customer but it offers sustainability advantages through economies of scale. Cloud service providers run multiple customers on the same hardware fully utilizing the underlying infrastructure reducing the overhead associated with customers running the infrastructure themselves. This sustainability guideline isn’t specific to AI, but certainly applicable.
Choose the Right Model Size
Whether you’re using a managed service or running your own model it’s important to choose the model that is sized appropriately for your task. Just as when sizing a server for an application you would choose a size appropriate to the workload, you should use the same approach when choosing the size of your AI model. Larger models are generally more computationally expensive to run, therefore requiring more GPUs, increased energy, water consumption, and a larger carbon footprint. Larger models are also typically slower.
AI vendors typically give you access to different sizes in a single model “family”. They’ll give you a “small”, “medium”, and “large” where the larger models tend to be more intelligent but slower and more expensive. Anthropic does this with their family of Claude models named Haiku, Sonnet, and Opus.
There are different approaches you can take to choose the appropriate size of a model. It’s best to read the vendor’s prompting guide and documentation to get their recommendations for each model. Err on the size of a larger model at first to get your use case working and develop a set of tests that verify the answers are working. Then try the tests with a smaller model. You’ll typically find a few of your tests are failing on the smaller models. If you can address those issues through prompt improvements then you’ll be able to use a model that’s cheaper, faster, and has a smaller carbon/water footprint.
Optimize Your Prompts and Responses
Optimizing prompts and responses can significantly cut down the computational resources required for each task, which in turn reduces energy use and operational costs. By refining how we interact with AI models, we can achieve powerful results while also supporting more sustainable and responsible AI practices. This applies not only to general LLM usage but also, as we’re focusing on here, to building applications that interact with AI via prompts.
Smaller prompts and responses generally require less energy for a few reasons.
- LLMs work by processing input tokens through multiple layers so fewer tokens in the input and output reduce the overall work the model has to perform.
- Smaller input and output sizes can lead to lower memory usage helping to reduce the energy needed to store and manage data.
- Less data to process also results in faster inference times, reducing the overall time using the CPU and GPUs.
Here are some general guidelines for optimizing prompts and responses for reduced energy usage when you’re building applications that use Generative AI:
- Try shorter variations of your prompt to see if the same performance can be achieved with shorter prompts. You can ask the LLM to help you optimize a prompt to be clear but succinct and it will generate better prompts for you.
- Eliminate redundancy in the prompt. Sometimes redundancy can be used to help remind the LLM of important rules. There are other ways to improve the LLM response. Read the prompting guide for your LLM model to get the best results.
- Use JSON Mode and similar features to have the LLM output only the specific data needed in a response. If you need the LLM to indicate a true or false answer, have it return a 0 or a 1 or single word response instead of a long sequence of text.
- Use techniques like Chain of Thought where the LLM is asked to explain why it’s making a particular decision only when needed. These techniques are used to improve the final answer because it has time to “think” by generating tokens and tying the probability of the final answer
- including the prior tokens in its response. However, all of this requires more energy for processing a greater use of GPU resources.
- When possible avoid long conversations with multiple back and forth messages between the user and the LLM. Every time a user sends a subsequent request the entire conversation, including the answers the LLM provided, is sent back to the LLM for processing which can often be a huge number of tokens to process.
- Use prompt caching when available. Prompt caching is a new feature for both Anthropic and OpenAI that works by keeping input tokens cached for subsequent requests. Neither of them have confirmed that prompt caching reduces energy used, however the description of how this works leads us to believe that this would remove a non-inconsequential amount of processing resulting in less energy used. Prompt caching can also lead to lower costs which is typically a good proxy for the amount of energy used in a cloud service.
Choose Regions with Cleaner Energy
This is another general guideline, but very applicable. When spinning up cloud services, you generally select a geographic region for that service. Choosing a region powered by renewable energy resources will reduce the carbon footprint of your application.
You also want to consider data transmission and data egress. If your data is in one region and your services are in another, the data will need to be transferred to the service region, incurring data egress costs and using energy.
Amazon Web Services has published guidelines for choosing a region based on sustainability goals.
Moving forward
As AI continues to impact our work and lives, it is imperative that we take measures to minimize the impact on our planet. Element 84 is committed to sustainable development and AI use.
with less than 20% cloud coverage in 2021”
If you’re interested in learning more about our recent work utilizing generative, sustainable AI and related concepts including in federal contracts, natural language geocoding, and beyond, you can find more information on our blog. To get started using AI to address your organization’s big questions in a sustainable way, we’d love to connect. You can reach out to our team directly on our contact us page!
Written and researched by Jason Gilman and Lauren Frederick.

