
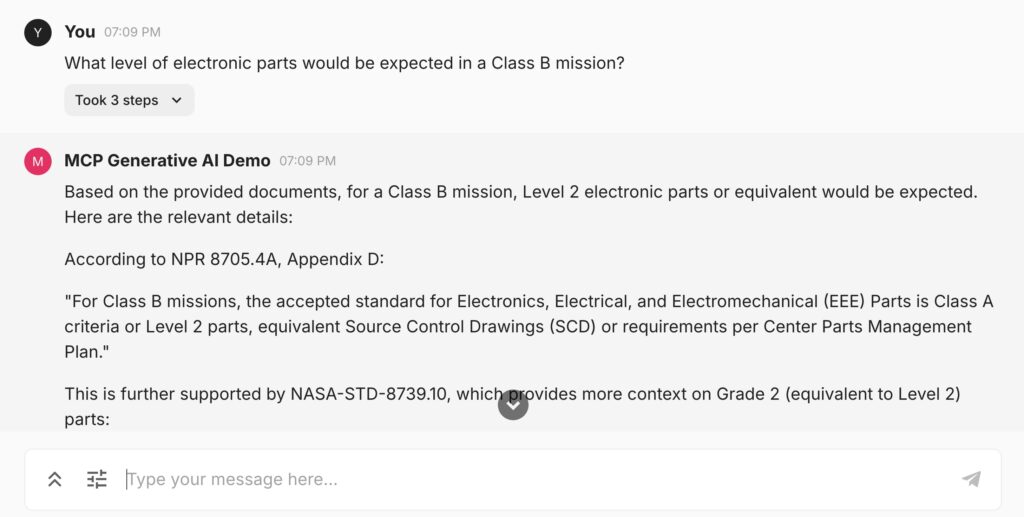
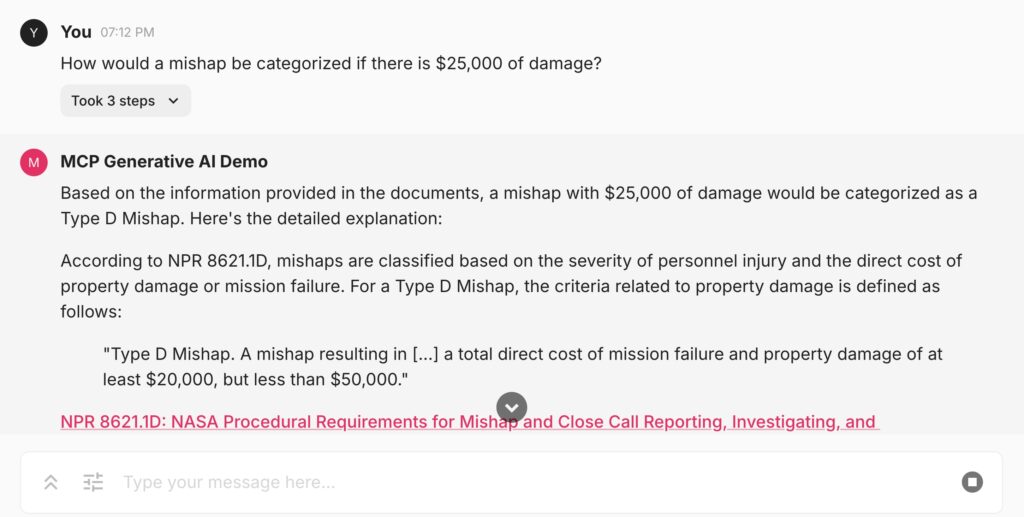
What is NASA Atlas?
We recently had the opportunity to build a Generative AI solution at NASA as part of NASA 2040, an agencywide initiative. NASA Atlas allows staff to ask technical questions answered by information from NASA standards, directives, procedures, and Space Act Agreement data. Atlas is able to answer questions relating to a wide range of topics, including federal employee leave, health impacts in space, material science, and risk management. We were able to achieve a high level of accuracy through a variety of methods including having access to experts to evaluate responses and provide guidance.
How did Atlas get started?
We work on NASA’s Mission Cloud Platform (MCP), a cloud environment supporting many NASA missions with hundreds of cloud accounts, alongside other NASA contractors. Our team was excited about the potential impact of generative AI in this work, and showed a small demo to the MCP program manager, Joe Foster, and Goddard’s deputy Chief AI officer, Matt Dosberg.
Both Joe and Matt were interested in helping to gain approval for generative AI within NASA and building demos that could showcase the art of the possible. This also aligned with the goals of NASA 2040, an agencywide initiative designed to accelerate and align planning for the necessary workforce, infrastructure, and technology capabilities of the future. We love working with NASA, and specifically love working within the MCP. The culture at NASA is receptive to new ideas. We really appreciate Joe and Matt’s vision, their encouragement and high standards, and willingness to let us try new things.
After officially deciding to introduce generative AI into this project, we kicked off the foundation of what would become NASA Atlas. The first few steps of the Atlas solution involved researching different approaches for building a Retrieval Augmented Generation (RAG) pipeline for answering user questions. We also worked to gain approval for Generative AI work under our existing authorization to operate (ATO).
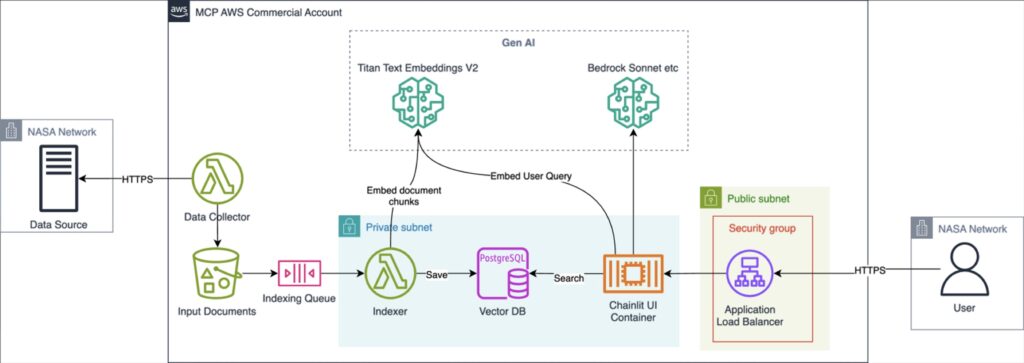
Our process, and what we learned along the way
We were able to achieve high accuracy with Atlas, and the feedback we received from various users has been outstanding. A NASA flight surgeon said that Atlas’s answers on health in space questions were “spot on”. Getting to that level of quality wasn’t easy, and we developed this while still meeting our day-to-day responsibilities on the MCP. We appreciated that after one initial demo at NASA Headquarters they pushed us to keep improving answer quality, increasing speed, and ensuring that this work met NASA’s high standards.
Due to the natural skepticism that often accompanies introducing Generative AI to a project, it is important to make a good first impression. If you’re looking to introduce Gen AI into your own work, we’ve compiled some of the more salient lessons we learned throughout the process.
Lessons learned during our work on Atlas
- Bringing in experts is critical
Building a generative AI tool like Atlas means building a system that can answer a wide variety of questions touching on a variety of domains. Our expertise lies in the cloud, software engineering, and geospatial solutions, so we aren’t necessarily qualified to determine if questions on material science or specific rules for differentiating NASA Mission classes are complete and accurate. We were able to gain access to experts who could communicate what they expect from a “good” answer. These experts also can test the solution at hand to determine if answers are incorrect or missing information. Being able to iterate with this feedback helped us to achieve our desired results.
- Sometimes answers will surprise you
In some circumstances we heard that answers to specific questions were wrong, but, after digging into the source documents, we realized that the guidance around that given subject had changed. A system like this can even help someone who’s very familiar with an area to learn something new.
- Spend most of your time on data preparation
Getting good answers from a RAG system depends on being able to provide the relevant text to an LLM. The text needs to be unambiguous, complete, and relevant to the question. To meet this high standard, the number one most important element is data preparation. When we found that answer quality was lacking, it usually stemmed from text chunks that had irrelevant text in them. This can be avoided by removing extraneous data from pdf sources, or extracting text from sources like HTML, which are naturally divided into sections.
Although it can be tedious, it is hugely beneficial to manually review the chunks that are extracted. If they’re readable and understandable to you, they’ll probably be that way to the model.
- Test and experiment with chunk sizes and embedding models
Throughout our process, we ran tests to see if varying chunk sizes impacted the results. We found the ideal chunk size for this particular project. Similarly, we were able to select an appropriate embedding model from Amazon through trial and error.
- Frameworks like LangChain can add unnecessary complications
Experimenting with LangChain was an important part of the trial phase for Atlas. Although we found that it was easy to use in the initial phases, we found that the complex class structure with many levels of inheritance made it difficult to customize or understand how to deviate from the default behavior. Ditching it freed us to completely customize our RAG pipeline and reduced the time to build a highly accurate system.
- Put the tabular data in a table and use generated SQL
NASA Space Act Agreements describe agreements NASA has made with other outside groups. They were distributed in PDFs in a table format. We wanted to allow advanced interrogation of this data and answering questions that involved performing calculations across multiple rows like, “What is the total cost of all agreements in 2021” or, “What are the top 5 most expensive agreements with company Foo”. Putting this data into a relational database and using an LLM to generate SQL to answer questions provided much better answers than trying to use the raw text.
- Amazon Bedrock’s access to models has been great
Throughout this process, Bedrock served to do just what we needed: provide great models with an easy-to-use API at a reasonable cost. Models show up in Bedrock the same day as they do in Anthropic, and you don’t have to run models yourself which results in an easier and more cost-effective workflow.
- Amazon Aurora PostgreSQL with pgvector installed has a low base price and is fairly easy to useВ
We preferred this to the Opensearch Serverless option that has a minimum monthly cost of about $700. That said, OpenSearch Serverless is required to use the Knowledge Base features in Bedrock. Knowledge Base makes it easy to get started and provides a good default, but we appreciated having complete control in our implementation to add in other capabilities by building our own RAG implementation. One example of additional capabilities includes asking questions which require different approaches such as generating SQL or using prebuilt summaries of documents.
NASA Atlas going forward
This is an undeniably exciting project due to the opportunities it reveals for letting users explore existing huge knowledge bases. Our team at Element 84 is looking forward to seeing how AI and ML will continue to manifest within NASA projects. Atlas has huge potential when it comes to solving complex problems, and there are undoubtedly countless solutions that could be improved or informed by implementing related AI technologies.
If you’re interested in learning more about NASA Atlas and our Generative AI work more generally, we’re regularly sharing more on this topic over on our blog and in our quarterly newsletter. If you have specific ideas or questions relating to this work, feel free to chat with our team directly over on our contact us page.