
This week, our team published a detailed white paper in which we make the case for how Earth Observation (EO) data providers such as NASA can dramatically improve access to their data by creating a centralized vector embeddings catalog, in addition to the more standard data catalogs that they already maintain. We argue how this effort aligns well with NASA’s declared goals of accelerating data discovery and why NASA is uniquely positioned to undertake it. We further lay out a phased program for building this catalog and discuss important challenges and risks that will need to be addressed along the way.
This topic is top-of-mind for our team because we’ve been engaged in many conversations recently about the future of the EO Industry. Through these discussions, we’ve picked up on barriers to use of EO data. There is lots of data available, but it continues to be difficult for users to find the data that they need. Users have to download and process huge files, and, beyond their own expertise in climatology, atmospheric, environmental, or analytical fields, they need to understand software engineering and machine learning.
We believe that a catalog of vector embeddings can directly address these kinds of user challenges and open up new possibilities for understanding remote sensing data. EO Foundation Models, having been trained on millions of geographically diverse data points, have the ability to convert raw EO data into vector embeddings, a compressed semantic representation of the data. Our team has been researching the potential of vector embeddings for several years to help meet this need – you can read more about this work in our previous blogs focused on implementing vector embeddings as a resource for change detection. Indexing these vector embeddings into a catalog that indexes data spatially, temporally, and by feature similarity, would create a powerful tool that would make it possible to search within the contents of the EO data itself. Users would be able to directly query complex phenomena like agricultural areas showing drought stress, illegal mining operations, or construction projects in flood zones without specialized technical knowledge. They would also be able to quickly search for changes over time, such as an increase in conditions leading to potential wildfires.
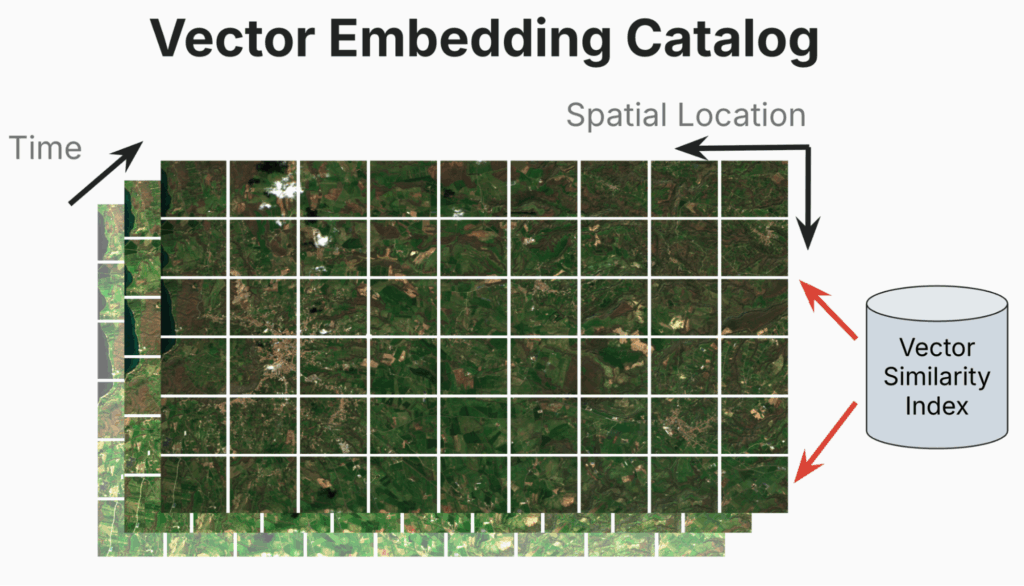
In the white paper, we show the many benefits of creating a catalog which include the following:
- Democratizing use of EO data – Searching for the needle in a haystack or finding specific changes is now possible without advanced geospatial or ML skills.
- Accelerating Science – Instead of spending weeks downloading and processing terabytes of imagery to identify relevant datasets, users can query a catalog in seconds to find exactly what they need.
- Infrastructure Cost Reduction – Embeddings can represent the original data at a compression ratio of 250x or more reducing data transfer and processing costs.В
- A Research Catalyst Effect – A catalog of vector embeddings could provide a standardized foundation on which a broader community can build novel applications.
We build on these ideas, outline potential risks and mitigations, and list strategic steps to evaluate these ideas within your own organization. To read further, check our full white paper. You can find it directly on GitHub here, or alternatively, have it sent straight to your email inbox if you pass along your email address.
Want a PDF of the white paper in your inbox?
Next Steps and Collaboration
We’re ready to start putting these ideas into place and look for new ways to build on these ideas. There are several concurrent attempts to create a vector embeddings working group going on now. We’ll post information on how to participate in those once they’re set up.
If you’d like to discuss vector embeddings or any other elements of this white paper in greater depth, we’d love to hear from you! Our team is accessible at any time on our contact us page.


