The landscape of geospatial AI is rapidly evolving. Many organizations are building LLM-powered solutions that tackle complex geospatial problems and answer sophisticated questions about our planet. These agentic approaches allow LLMs to autonomously select from toolsets that include geospatial tools, Earth Observation (EO) catalogs, and EO data processing capabilities. The result? Systems that can process actual data and generate maps, time series analyses, and aggregate results in response to user queries.
At the heart of these capabilities lies a fundamental challenge: understanding what users are actually asking for. When someone poses a geospatial question, we need to decode several key elements:
- The problem they’re trying to solve
- The specific areas on Earth they’re referencing
- The relevant time periods
- The type of data required
- How that data needs to be processed to provide an answer
While many current agentic and LLM-based systems support basic location specification, like naming “Los Angeles County” or drawing areas on a map, we recognized the need to go further. Users should be able to describe spatial areas using natural language the same way they would describe it to another person.
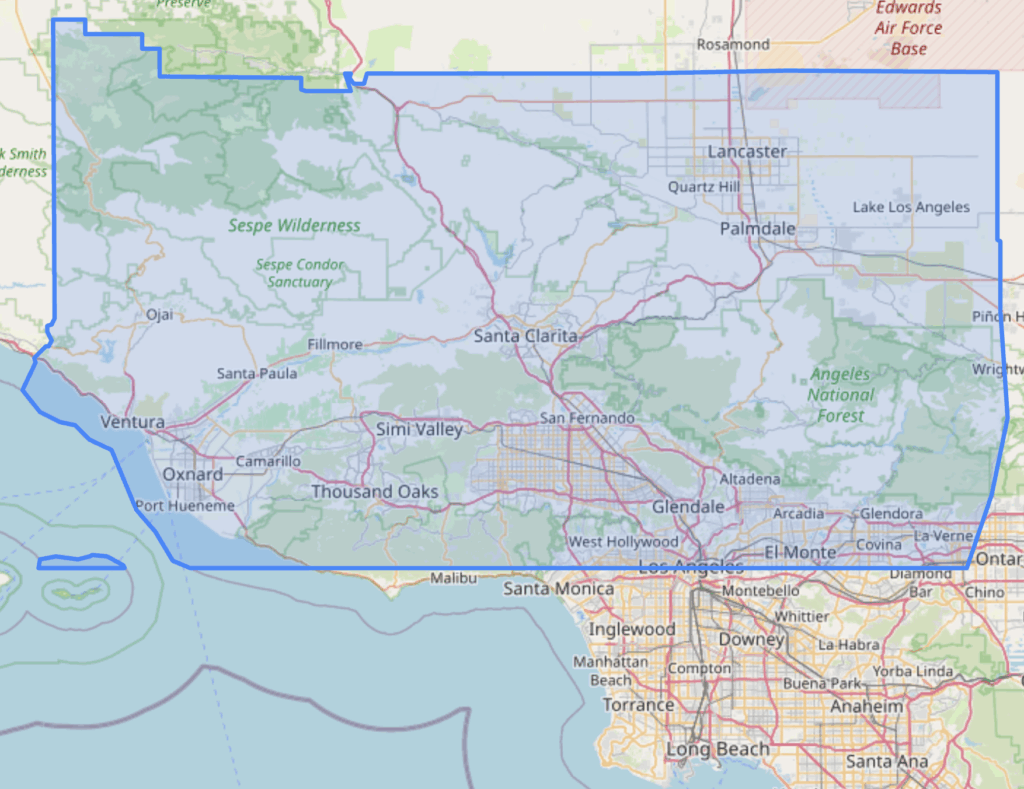
For example, “Find active forest fires in Los Angeles and Ventura Counties, north of Santa Monica” identifies the following area:
This vision led us to create Natural Language Geocoding, and today we’re excited to announce version 0.1.0, a significant evolution that transforms our library into a comprehensive LLM-enabled geocoding database.
What is Natural Language Geocoding?
Natural Language Geocoding is an open source Python library and geocoding database that converts natural language descriptions of areas on Earth into precise geometry. Rather than limiting users to simple place names, it enables complex spatial descriptions by leveraging LLMs to generate graphs of spatial operations, including place lookups, boundary calculations, coastline analysis, unions, intersections, differences, buffers, and more.
Since its initial creation in spring 2024, we’ve been actively developing and deploying Natural Language Geocoding across multiple projects in various domains. The project has gained attention in the geospatial community, with features in our original blog post, the Mapscaping podcast in July 2024, and a presentation at State of the Map US 2024.
What’s New in Version 0.1.0
Version 0.1.0 represents a fundamental shift in our approach. We’ve moved from a library that utilizes existing open source databases to creating a comprehensive LLM-enabled geocoding database with its own extensible collection of places. The centerpiece of this update is our transition from Nominatim, the API behind Open Street Map, to a custom geocoding database built on OpenSearch.
Why We Moved Beyond Nominatim
This transition wasn’t made lightly. While Nominatim serves the OpenStreetMap ecosystem well, we encountered several limitations that led us to develop our own solution:
Usage Constraints: Nominatim’s public API isn’t designed for heavy production usage, and its terms of service reflect this limitation.
Hosted Deployment Complexity: We considered running our own self-hosted Nominatim instance, but that requires self managing a PostgreSQL database with custom plugins developed by Open Street Map, adding database administration overhead we preferred to avoid.
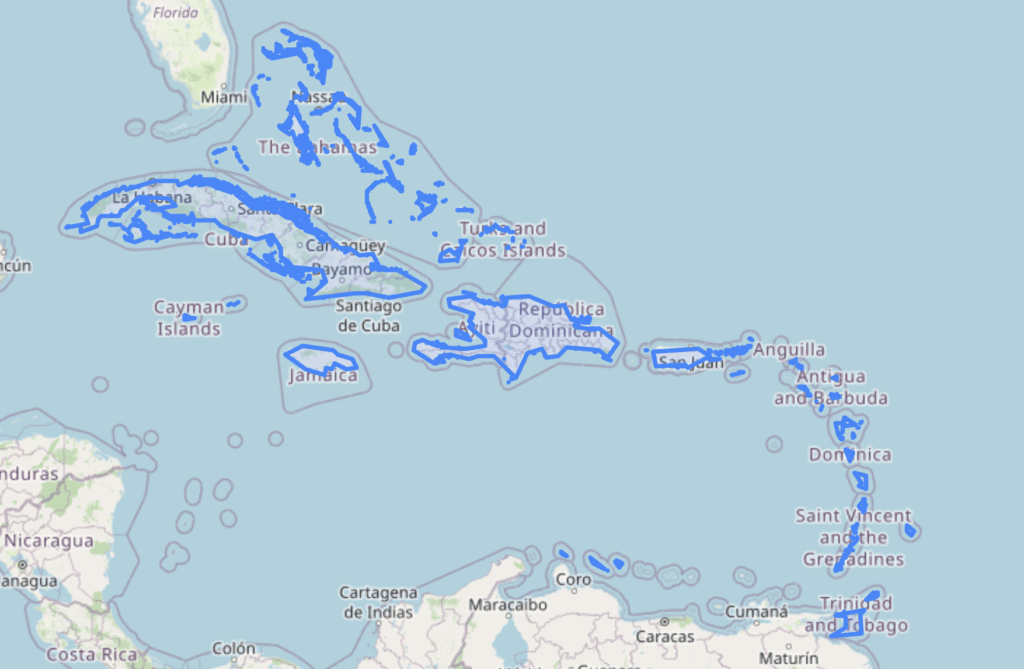
Extensibility: We wanted the ability to add places that don’t exist in traditional geocoding databases, such as the Sargasso Sea, West Africa, or “The Caribbean” as a reference to the entire archipelago.
Relevancy Control: We needed greater control over result relevancy to ensure users find the exact areas they’re looking for. When the system returns the wrong area, it undermines the entire user experience. The lack of control over result ordering meant users might not get the most relevant location first.
Polygon Emphasis: Our core use case requires polygons, not just point coordinates. We need the actual boundary of locations like “Annapolis, MD”, not just the center point. Many Nominatim places lack polygon data, and other geocoding databases we investigated didn’t prioritize polygons sufficiently.
The New Geocoding Index
Our new geocoding database follows the path of other open source geocoding databases of populating data through ingesters that pull from public data sources. Currently, we’re ingesting from Who’s On First and Natural Earth, with plans to integrate Overture Maps data in future releases. This approach positions LLMs as an intelligent front-end to rich geospatial datasets.
The initial release includes more than 5 million places in the database. Our design prioritizes several key features:
Comprehensive Polygon Coverage: We ensure as many places as possible include polygon geometry rather than just point coordinates.
Hierarchical Context: The system maintains awareness of geographical hierarchies, understanding relationships between continents, countries, states, and local areas.
Alternative Names: Places are indexed with their various names to improve discoverability.
Intelligent Place Resolution
One of the most challenging aspects of geocoding is disambiguation, finding the right place when multiple locations share the same name. Our system addresses this through several approaches:
Contextual Understanding: The system analyzes details in user questions to determine which location they likely mean. For example, a query about mentioning just “Portland” would choose the city in Oregon because it has a higher population than the one in Maine, but “Identify lobster fishing locations near Portland” chooses the city in Maine.В
Type-Specific Search: Users can search for places by specific types from an extensive list including countries, continents, wetlands, rivers, seas, oceans, ports, national parks, and islands. They don’t have to specify the type themselves as the LLM can determine that from the user’s query.
Hierarchical Context: The system understands geographical hierarchies, allowing for searches within specific continents, countries, or regions.
Fuzzy Matching: Built-in handling of misspellings ensures users can find places even with imperfect spelling.
Intelligent Scoring: Results are ranked by multiple factors including name similarity, place types, source reliability, and population, with preference given to well-known locations over obscure ones.
Composed Places and Custom Locations
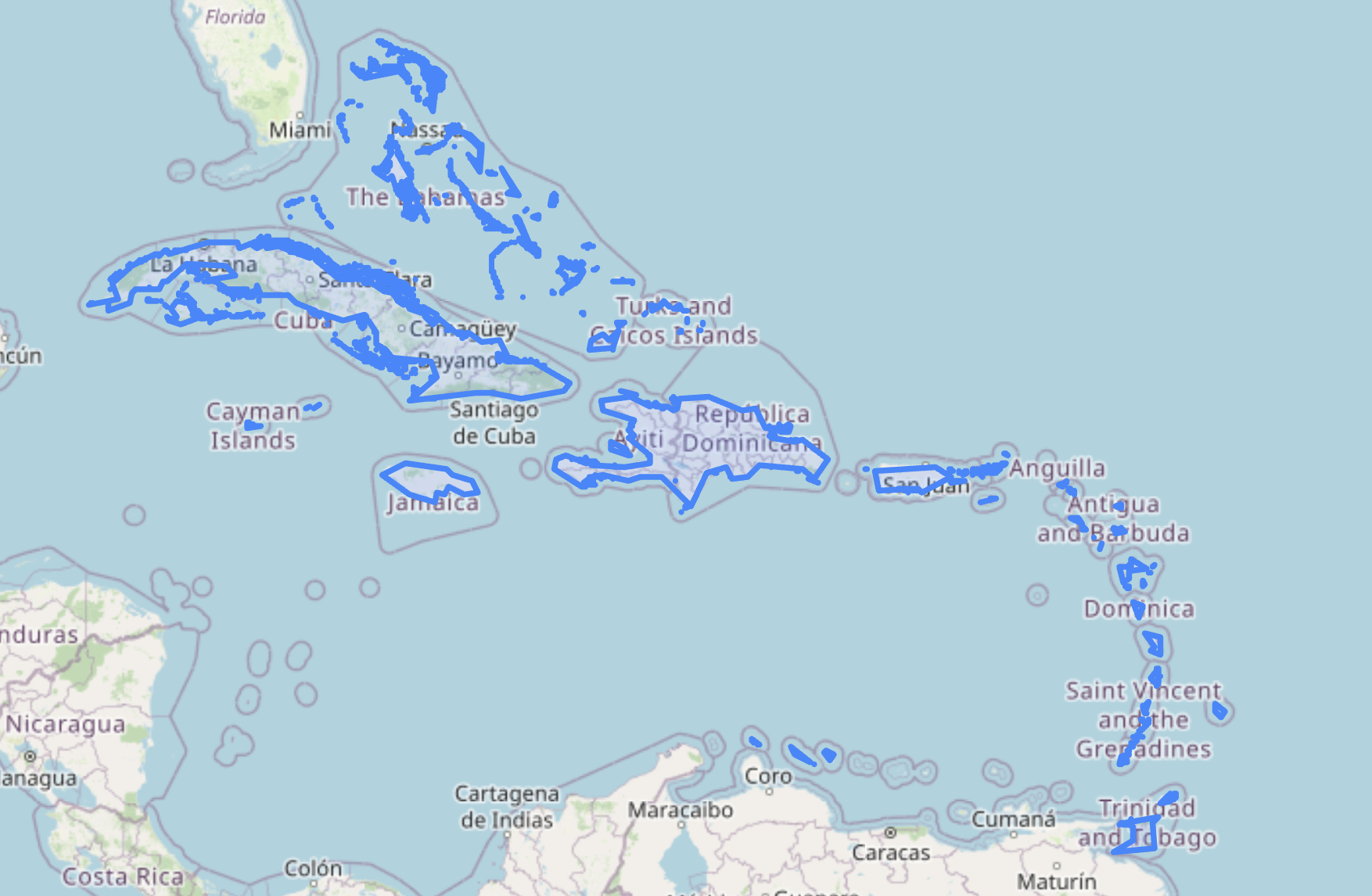
Beyond individual places, our database includes larger regions composed of multiple smaller areas. These “composed places” enable references like “the Caribbean,” which encompasses 27 individual countries, regions, and dependencies.
The system also supports adding custom locations, enabling organizations to include specific areas relevant to their use cases and supporting localization for different languages.
Additional Improvements
Version 0.1.0 includes several other enhancements:
Automated Evaluations: We’ve implemented comprehensive testing scenarios to validate the LLM’s ability to produce correct results across various use cases which helped us identify improvements we could make to the overall system.
Enhanced Spatial Relationships: Improved handling of phrases like “off the coast of” for more nuanced geographical relationships.
Better Conjunction Handling: More sophisticated processing of complex queries involving multiple locations or conditions.
Claude Sonnet 4 Integration: Updated to leverage the latest LLM capabilities for improved accuracy and understanding. Can be configured with different models.
Complex Geometry Management: Enhanced handling of very complex geometries with automatic simplification options for downstream applications.
Looking Forward
Natural Language Geocoding v0.1.0 represents a significant step toward making geospatial AI more accessible and powerful. By creating a purpose-built geocoding database optimized for natural language interaction, we’re enabling more intuitive and sophisticated geospatial queries.
As we continue development, we’re excited about integrating additional data sources and exploring new ways to make geospatial intelligence more accessible to users regardless of their technical background.
The future of geospatial AI lies in systems that understand not just what we’re asking, but the nuanced ways we naturally describe the world around us. Natural Language Geocoding v0.1.0 brings us closer to that vision. Reach out to our team directly on our contact us page to chat more about Natural Language Geocoding and to get involved.
Natural Language Geocoding is available as an open source project on GitHub and PyPI. We welcome contributions, feedback, and collaboration from the geospatial and AI communities.
