
Increased efficiency is desirable across all sectors including the federal government. Generative AI has the potential to transform federal government services through task automation, improved efficiency, improved accessibility, data analysis, and education. Although Generative AI is relatively new to the majority of the federal government, most federal agencies have an existing cloud presence with a cloud provider such as Amazon Web Services (AWS). In this blog post we’ll show you how to get started with Generative AI in your existing cloud accounts.
Risks and benefits of implementing Generative AI
Like with most new technologies, there are both dangers and opportunities that come with the implementation of Generative AI. Specifically, Generative AI has the potential to greatly improve efficiency through indexing the vast corpus of knowledge used in the governmental sphere. Furthermore, it provides an accessible path for federal employees to ask questions and receive answers with citations from original sources in return. Natural language can improve accessibility for all people through making information easy to find, understandable through natural language comprehension, and by offering services in multiple languages. Finally, predictive analyses of time series data can provide trends that inform decisions around climate change, policy impacts, and public health.
It’s critical that federal employees and contractors begin to safely experiment with these technologies now so they can learn their capabilities, drawbacks, and challenges such as minimizing hallucinations. During experimentation and testing it’s important to follow federal guidelines and security requirements. Federal administrators must also guide their staff to ensure safe adoption of the technology. Without guidance, staff may use “Shadow IT” approaches and start signing up for online services without an Authority To Operate (ATO) potentially leaking confidential information or producing products that aren’t properly vetted.
Generative AI Adoption Challenges
While there is a clear need for the adoption of Generative AI in the federal space, there are several challenges that need to be tackled before it can be implemented fully.
As is the case with any new technology, training will be necessary to guide your existing staff and to introduce safe use and proper applications of the technology. Generative AI is also a new area for government agencies in general. For this reason, official guidance may not exist yet, or may limit uses to only publicly available information.
Building a Simple Chatbot Using Retrieval Augmented Generation
Because federal agencies have large corpuses of public information, the ability to ask questions about those documents in natural language and get answers with cited sources would greatly improve the day-to-day processes of governmental employees. We can meet this need using Generative AI technologies by generating a chatbot able to accurately respond to questions about specific documents. This is also a great way to get started, because it doesn’t require specialized machine learning knowledge and open source models can be used without any fine tuning. Building an internal only prototype using Generative AI is an opportunity for learning within your organization while simultaneously gaining confidence from stakeholders.
We’ll use the approach of Retrieval Augmented Generation (RAG) to build our chatbot. There are many great overviews of RAG, so we will keep it brief. As a basic overview, it works as follows:
- Source documents are broken into chunks and stored in a Vector Database. A vector database allows searching for semantically relevant text.
- A user submits a question like, “How does this federal agency support climate resilience?” in a chatbot interface.
- The question text is converted into a Vector embedding using a Text Embedding Model. A vector embedding is just a list of numbers that represent the semantic meaning of the question.
- The UI searches the vector database for document chunks that could answer the question. To accomplish this, the vector database computes the distance between the question’s vector embeddings and the document chunk embeddings. A short distance means this document chunk likely can answer the question.
- The UI takes the most relevant document chunks and sends them to the LLM along with the user’s question. Basically, the LLM gets a request that says, “Answer this user’s question. Here’s a list of excerpts from the documents that may help answer it.”
One of the great benefits to RAG is that an off-the-shelf LLM can be used without any fine tuning.
Using Generative AI in AWS Bedrock
The AWS service Bedrock provides many of the different components necessary to build RAG solutions. Bedrock has the following:
- Many foundation models are available for the LLM like Claude and Mistral AI.
- Text embedding models for converting the document chunks or user question into Vector embeddings.
- The ability to implement the entire RAG chain from indexing to generating a prompt for the LLM (because Bedrock Knowledge Bases is a managed capability).
- Serverless Vector Database support through OpenSearch with automated indexing.
Even with these components Bedrock is not a perfect solution, and full adoption has a few primary limitations:
- Bedrock is not FedRamp approved yet (but it is in progress).
- While Bedrock in AWS Commercial has many models available, Bedrock in AWS GovCloud only has a single model available for now.
- For small tests, the serverless OpenSearch can be a bit expensive. It requires a minimum of 2 compute units always running, totalling approximately $730 a month.
After Bedrock is Fedramp approved, it will probably be the easiest way for the federal government to build LLM approaches in AWS.
An approach for testing RAG in AWS
If you’d like to get started building out RAG now and are restricted to only FedRamp approved services or must run in GovCloud, here’s an architecture that uses all FedRamp approved services and works in AWS commercial or GovCloud. It’s a bit more advanced than the intro RAG tutorials, but it gets closer to what a production RAG system would look like excluding things like scalability on the LLM side, monitoring, guardrails, etc.
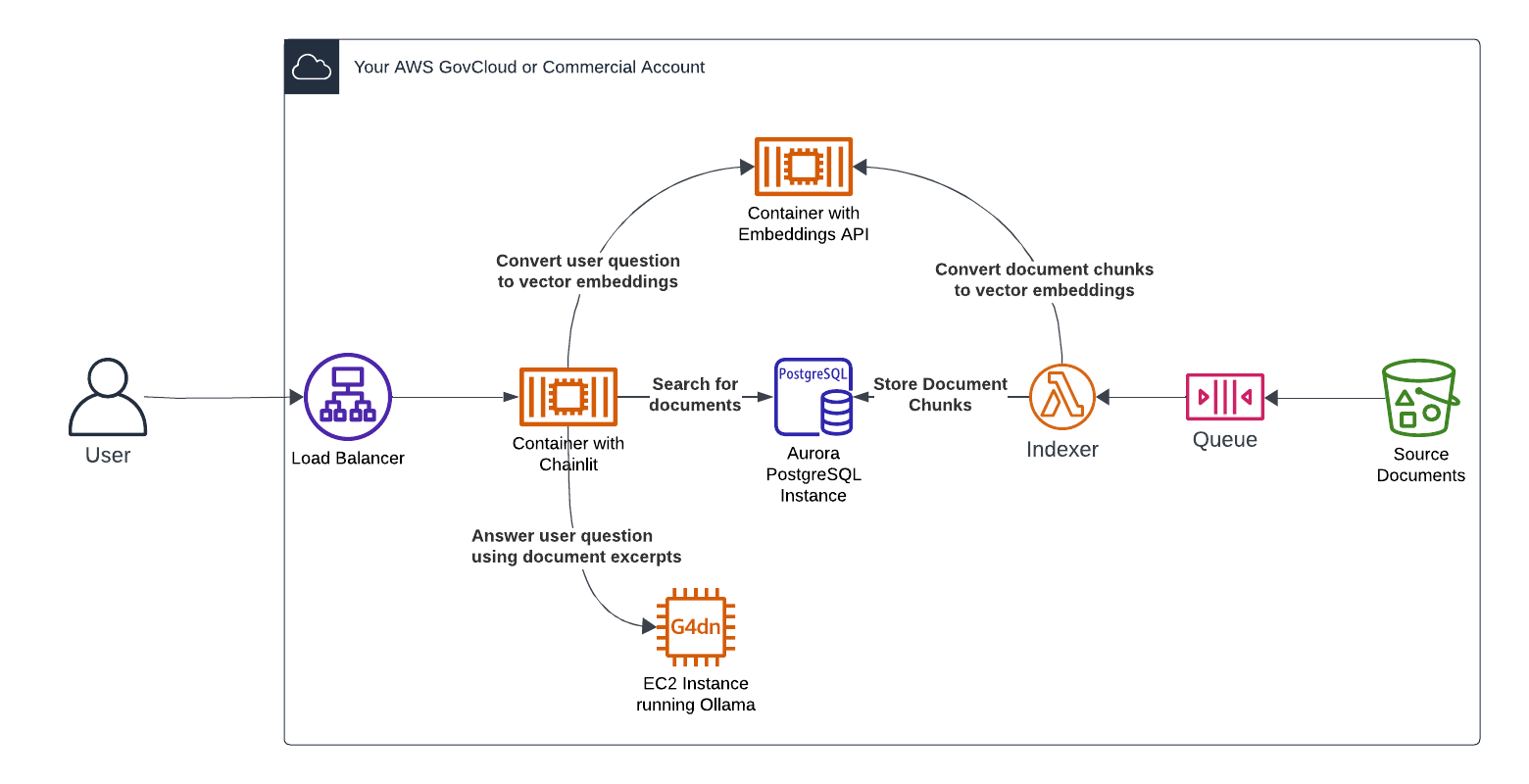
This architecture uses Open Source software and models on FedRamp approved services. All of the data and software is kept in your account, so no third parties services are involved. This requires a small amount of Python coding but it will give you familiarity with LLMs and related technologies. Parts can be swapped out later as Bedrock gains Fedramp approval and more features arrive in GovCloud.
AWS Components
- S3 Bucket – Stores documents to index
- AWS Lambda Indexer – Reads read the documents from S3, chunk them, uses the embeddings API to create vector embeddings, and then saves it to the vector database
- Aurora Postgres RDS database – This is a standard Aurora PostgreSQL database instance with the pgvector plugin installed.
- Text Embeddings Container – Runs the HuggingFace Text Embeddings Inference API. This is an easy API to stand up that can provide embeddings from open source models. It’s easy to package as a container and doesn’t need expensive hardware or a GPU to run.
- LLM instance – The easiest way to run an LLM on an EC2 instance is to use Ollama. It has a very simple install and then can download and run many open source models.
- Chainlit UI Container – Chainlit is an open source application framework that makes it easy to stand up a chat bot like UI in front of an LLM system.
Software
We’ve mentioned some of the open source software used in this process already like pgvector, Ollama, and Chainlit. Tools like LangChain and LlamaIndex are open source Python frameworks for developing applications powered by large language models. In the Lambda Indexer you will need code to convert documents into chunks, generate embeddings, and store the data in the vector database. In the Chainlit container you’ll need code to take the users request, search the vector database, and invoke the LLM. Libraries like LlamaIndex can help with both of these. See the LlamaIndex docs for information about how to build RAG like solutions. Chainlit also has examples of integration with LlamaIndex and cookbooks for things like packaging as a container. Note that our original implementation was done using LangChain. Due to challenges with the complexity of LangChain we recommend using a different framework like LlamaIndex. This sentiment seems to be shared by the community.
Continuing on Your AI/ML Journey
As you’re experimenting with Generative AI you’ll also need to think about compliance and operating within your existing security framework. You’ll need to answer questions and take actions like the following:
- What does your System Security Plan (SSP) say, who are your authorizing officials, and who will be verifying that the system is compliant?
- When it comes to NIST 800-53 controls which apply to all systems, how will you implement controls around data protection, access control, data leakage, third party access, as well as information diversity?
- How will you verify that your system meets the security requirements in your SSP with the additional controls and enhancements you’ve identified for Generative AI?
Element 84 has expertise not only in cloud infrastructure and AI/ML but also in helping federal agencies acquire Authority To Operate (ATO). We can help you develop the security plans and Generative AI security story that can earn the confidence of your authorizing officials.
We’d love to hear from you regarding your ideas for Generative AI and the challenges you’re facing. You can reach our team directly on our contact us page, and stay tuned for more related blog posts coming soon!
Authors
Jason Gilman, Andrew Pawloski